Border Gateway Protocol
Les protocoles de routage peuvent Ítre dťfinis en 2
catťgories: IGP et EGP
IGP (Interior Gateway Protocol) sont les protocoles de
routage qui ťchangent des informations au sein d'un Autonomous System. Les
principaux protocoles de type IGP sont: RIP, IGRP, EIGRP, OSPF.
EGP (Exteror
Gateway Protocol) sont des protocoles de routage qui servent ŗ conecter
(ťchanger des information de routage entre) 2 AS.
BGP-4 est un EGP dťfinit au
travers de la RFC 1771.
Le rŰle de BGP est d'annoncer les routes.
D'un
point de vue de BGP, les AS apparaisssent aux autres AS comme possťdant un plan
d'adressage interne cohťrant et qui se prťsente sous forme d'une entitť qui peut
Ítre utilisťe pour joindre d'autres destinations.
Le rŰle de BGP n'est pas de
jouer avec les mťtriques mais d'annoncer les routes et de s'assurer qu'il
n'existe pas de boucles de routage entre les AS.
BGP est le successeur d'EGP.
Il est utilisť par les ISPs entre eux ou dans certains cas pour connecter de
gros clients aux ISPs.
|
Protocol |
Interior or Exterioir |
DV or LS |
Hierarchy Required |
Metric |
|
OSPF |
Interior |
LS |
Yes |
Cost |
|
EIGRP |
Interior |
Advanced DV |
No |
Composite |
|
BGP |
Exterior |
Advanced DV |
No |
Path vectors or attributes |
LS pour Link State
DV pour
Distance Vector
OSPF utilise le cost basť su la bandwidth en tant que
mťtrique.
EIGRP utilise un mťtrique composť basť essentiellement sur la
bandwidth.
les routeurs qui utilkisent BGP s'ťchangent des informations
d'accessibilitť de rťseau appelť path vector ou attributes, qui inclue une liste
complŤte de path (BGP AS numbers).
BGP est plus appropriť quand l'une des
conditions suivantes existe:
- Un AS permet ŗ des paquets de transiter par lu pour joindre d'autres AS, comme c'est le cas pour un ISP.
- Un AS qui dispose de plusieurs connexions ŗ d'autres AS.
- Si le flot de trafic qui entre et qui ressort de l'AS doit Ítre manipulť.
BGP, s'il n'est pas contrŰlť et filtrť proprement, a le
potentiel de permettre ŗ un AS extťrieur d'affecter les dťcisions de routage
locales.
Un routeur BGP connectť ŗ Internet dispose d'une table de routage
supťrieure ŗ 30MB, dťcrit plus de 70000 routes et renseigne plus de 6500
ASs.
Il est des situations oý BGP n'est pas appropriť:
- Une seule connexion ŗ Internet oe ŗ un autre AS.
- Les conditions de routage et les sťlections de routes sont indťpendantes de votre AS.
- La taille mťmoire ou le type de processeur de votre routeur ne sont pas assez puissant pour supporte des updates constants.
- La limite de comprťhension du filtrage de route et du process de sťlection des chemins de BGP.
- Une bandwidth faible entre les AS.
Dans ces cas il convient d'utiliser des routes statiques pour
interconnecter les diffťrents AS.
router(config)# ip route prefix mask
{address |interface} [distance] -->crťe une route statique,peut ťtablir
une route flotante.
Une route flotante est une route qui dispose d'une
administrative distance plus grande que la route issue du protocole de routage.
Ainsi ce type de route sera employťe quand la route primaire tombe, on crť un
"path of last resort".
exemples:
RIP:
ip
route 0.0.0.0 0.0.0.0 S0
!
router
rip
network 172.16.0.0
OSPF: la configuration par
dťfaut d'OSPF utilisant une route statique:
ip route 0.0.0.0 0.0.0.0 S0
!
router spf 111
network 172.16.0.0 0.0.255.255 area0
default-information originate always
1. Les caractťristiques de BGP
BGP est un rpotocole de type distance vector avec des amťliorations:
- support d'updates sŻr, BGP tourne qudessus de TCP et utilise le port 179
- updates incrťmentaux et programables
- envoi de keepalives pťriodiques pour vťrifier la connexion TCP
- dispose d'un mťtrique riche appelť path vector ou attributes
- est conÁu pour supporter des rťseaux trŤs larges (Internet par exemple)
Du fait que BGP utilise directement TCP, il n'a pas besoin de
mťcanisme de retranssmission d'erreurs en utilisant directemnt les mťcanismes
TCP. 2 routeurs qui utilisent BGP ouvrent une connexion TCP et ťchangent des
messages d'ouverture et de confirmation de conexions. Ces 2 routeurs se nomment
des peer routers ou neighbors.
Une fois la connexion ťtablie, l'ťchange des
tables de routage peut avoir lieu. L'ťchange des tables de rouage se fait sur
base de mises ŗ jour, updates incremetal. Les updates pťriodiques ne sont pas
nťcessaires sur une connexion ťtablie et maintenue. Cependant des triggered
updates sont utilisťs qui sont ŗ assimiler aux hellos packets envoyťs par
certains protocoles.
Les routeurs BGP s'ťchangent des informations
d'accessibilitť que l'on nomme path vectors formťs ŗ base de path attributes et
qui incluse une liste complŤte de chemins de BGP As numbers qu'une route peut
prendre pour se rendre ŗ destination. Ces informations de path sont utilisťes
pour construire un graph d'autonomous systems sans boucles et surlesquels des
policy de routage peuvent s'appliquer.
Les path sont loop-free parcq'un
routeur ne peut accepter d'updates de routage qui iclue son propre AS.
Il est
ŗ noter que sous BGP le voisin n'est plus forcťment le next hop, mais celui qui
arrive ŗ ouvrir une session TCP.
BGP comporte 2 tables:
- sa propre table dans laquelle on trouve qui ŗ envoyť et ŗ qui a ťtť envoyť l'info.
- sa table de routage
Les informations peuvent Ítre ťchangťes entre les 2
tables
Quand les neighbors se trouvent dans le mÍme AS , on parle d'internal
BGP: IBGP
Quand les neighbors se trouvent dans des AS diffťrents , on parle
d'external BGP: EBGP
1.1. Policy based routing
BGP permet aux administrateurs de dťfinir des policies, ou
des rŰles quant ŗ la faÁon que les datas peuvent traverser un AS.
BGP et les
outils associťs ne peut satisfaire toutes les polices (stratťgies) de
routage
BGP ne permet pas un AS d'envoyer du trafic ŗ un AS voisin, ŗ
condition que le trafic prenne une route diffťrente que celle que le trafic ŗ
utiliser ŗ partir de l'AS voisin (maÓtrise du chemin des datas).
Cependant,
BGP supporte toutes les polices conformťment au paradigm hop-by-hop routing
applicable donc en tant qu'inter-As routing (on peut influencer les routeurs
directement connectťs)
1.2. Les attributs BGP
Les BGP mťtriques BGP sont appelťs attributs.
Les updates
que les roueurs envoient ŗ propos des rťseaux de destination, incluent des
attributs.
Un attribut peut Ítre ŗ la fois well-known ou optionnel,
obligatoire ou discret, transitif ou intransitif et peut Ítre aussi
partiel.
Toutes les combinaisons de formes d'attributs ne sont pas
valides. En fait les attributs de path tombent dans 4 catťgories sťparťes:
- well-known mandatory
- well-known discretionary
- optional transitive
- optional nontransitive
Seuls les attributs tarnsitifs peuvent Ítre marquťs comme partiels.
1.3. Les attributs well-known
Les attributs well-known:
Ces
attributs doivent Ítre reconnus par toutes les implantations de BGP et sont
propagťs sur les voisins (neighbors).
Les attributs
well-known mandatory:
Ils doivent Ítre prťsents dans tous les
messages.
Les attributs well-known discrets:
Ils
peuvent Ítre prťsents dans tous les messages.
1.4. Les attributs optionnels
Les attributs optionels:
Ils sont reconnus par certaines
implťmentations et sont attendues pur ne pas Ítre reconnus par l'ensemble des
implťmentations.
Les attributs optionels reconnus sont propagťs aux autres
neighbors sur base de laur signification.
Les attributs optionnels
transitifs:
Si ils ne sont pas reconnus, ils sont marquťs comme partiel et
sont propagťs aux autres neighbors.
Les attributs nontransitifs
optionnels:
Ils sont dťtruits si ils ne sont pas reconnus.
2. Les principaux attributs BGP
Les attributs BGP incluent des attributs Well-known mandatory:
- AS-path
- next-hop
- origin
Welll-known discretionary attributes:
- local preference origin
- Atomic aggregate
Optional transitive attributes:
- aggregator
- community
Optional nontransitive attribute:
- Multi-Exit-Discriminator (MED)
- Weight (Cisco)
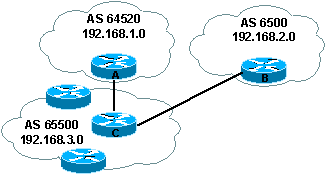
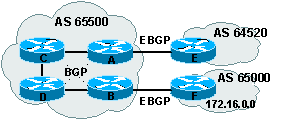
2.1. AS-Path
Attribut du type Well-known
mandatory. Il s'agit de la liste
des As ŗ traverser pour atteindre la destination.
Dans l'exemple
ci-dessus si on veut se rendre deouis le router B sur le routeur A il faut
passer par le routeur C. D'un point de vue de BGP, il faut emprunter l'AS 65500
et l'AS 64520 depuis l'AS 65000.
2.2. Next-Hop
Cet attribut est du type well-known
mandatory et indique le
next-hop address ŗ utiliser pour joindre une destination.
Pour EBGP le
next-hop est l'adresse IP du neighbor qui envoie les updates. DAns notre exemple
ci-dessus Le routeur A avertira le routeur B que le rťseau172.16.0.0 de l'AS
64520 est jpoignable par 10.10.10.3.
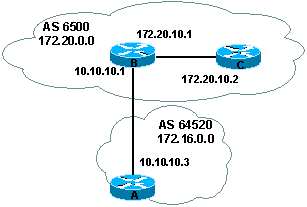
Pour IBGP le protocole assume que le next-hop avertit par
EBGP doit Ítre transportť dans IBGP. Du fait de ce rŰle, le routeur B avertira
172.16.0.0 ŗ son peer router IBGP qui n'est autre que C, avec un next hop ťgal ŗ
10.10.10.3. Ainsi C connaÓt en next-hop pour la destination 172.16.0.O le
routeur A d'adresse 10.10.10.3 et non pas 172.20.10.1 comme il se devrait.
Il
est donc trŤs important que le routeur C conaisse comment joindre le subnet
1.10.10.0 soit par un IGP soit par une route statique sosu peine de voire
ses paquets ŗ cette destination purement droppťs.
2.3. Netx-Hop sur un rťseau de type multiaccess
Sur un rťseau de type, BGP va utilser l'adresse correcte en tant que next-hop pour ťviter d'avoir ŗ insťrer des hops supplťmentaires dans le path. Cette caractťristique se nomme "third-party next-hop".
2.4. Next-Hop sur un rťseau de type NBMA
Dans ce cas les complications apparaissent.
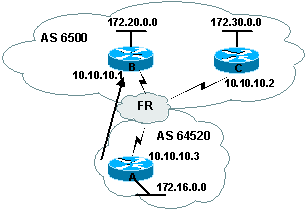
Dans notre figure, 3 routeurs sont interconnectťs en FR. Le
routeur B peut joindre le rťseau 172.30.0.0 par 10.10.10.2.
Quand le routeur
B envoie un update BGP au routeur A ŗ propos de 172.30.0.0, il va utiliser
10.10.10.2 comme next-hop et non pas sa propre adresse (10.10.10.1).
Un
problŤme va arriver quand les routeurs A et C ne savent pas directement
communiquer entre eux autrement dit si les routeurs A et C n'ont pas de map
entre eux. Le routeur A ne saura pas comment joindre la next-hop adresse du
routeur C.
Ce souci peut Ítre ťvitť en configurant le routeur B pour qu'il
s'avertisse lu mÍme comme next-hop pour les routes envoyťes au routeur A.
2.5. Les attributs de local preference
Local preference est un attribut well-known de type
discretionary qui donne donc une indication aux routeurs de l'AS sur le meilleur
chemin ŗ emprunter pour sortir de l'AS. Un path disposant de la locale
preference la plus ťlevťe sera prťfťrť.
La valeur par dťfaut pour les
routeurs Cisco est de 100. Cette valeur ne sera ťchangťe qu'au sein des routeurs
d'un AS.
Local preference ťquivaut donc ŗ un mťtrique en interne.
!Dans BGP le plus gros est toujours le
meilleur sauf pour le (club) MED
MED est ťquivalent ŗ un mťtrique, le milleur
est le plus bas.
2.6. L'attribut MED, qui n'a rien ŗ voir avec le club
MED est ťquivalent ŗ un mťtrique
en externe. Il est aussi connu en tant que Inter-AS
attribute dans BGP-3.
Cet attribut est ddu type optionnel
et nontransitif.
Cet attribut sert ŗ selectionner une route entre 2 AS quand
plusieurs choix existent. Cet attribut ne doit as Ítre transmis en interne.
Quand un update ŗ destination d'un AS contient un MED, et que ce mÍme update est
passť ŗ un autre AS, alors la valeur du MED passe ŗ 0 en sortie du 2į AS.
Par
dťfaut, un routeur ne va comparť le MED que sur les liens ou chemins entre les
neighbors d'AS.
En utilisant le MED, BGP est le seul protocole qui peut
affecter comment les routes sont transmises dans un AS.
2.7. L'attribut origin
L'attribut origin est du type well-known mandatory et dťfini l'origine de l'information concernant un path.
L'attribut origin peut prendre une des 3 valeurs suivantes:
- IGP, La route est originaire de l'intťrieur de l'AS, gťnťralement aprŤs avoir utilisť la commande network. Une origine depuis IGP est marquťe avec la lettre i dans la table de routage.
- EGP, quand la route est apprise depuis un protocole de type EGP, et porte la lettre e dans la table de routage.
- Incomplete, quand l'origine de la route est inconnue ou apprise d'une autre faÁon. En gťnťral c'est le cas quand une route est redistribuťe dans BGP. Dans ce cas c'est le caractŤre ? qui apparaÓt dans la table de routage.
2.8. L'attribut Community
Community=tag=nom. La community va servir ŗ ťtablir des
rŤgles de filtrage ou ŗ ťtablir des critŤres de sťlection des routes.
Chaque
routeur BGP peut tager des updatres de routes, entrants ou sortants ou lors
d'une redistribution.
Chaque routeur BGP peut filtrer des routes sur les
updates entrants ou sortants, ou selectionner des preferred routes basťes sur
les communautťs (tag).
Par dťfaut, les communautťs sont rťparties dans les
updates sortants.
Les communautťs sont des attributs optionnels et
transitifs. Si un routeur ne comprend pas les communautťs, il les passera telles
quel au routeur voisin. Par contre si le routeur comprend les communautťs, il
doit Ítre configurť pour les propagťr sinon elles seront dťtruites.
2.9. L'attribut weight (Cisco)
Il s'agit d'un attribut Cisco quant ŗ la sťlectionde path. Le weight est confugurť localement sur un routeur et n'est propagť sur aucun autre. Le weight peut avoir une valeur de ŗ ŗ 65535. Les paths originaire du routeur ont un weight de 32768 par dťfaut, les autres paths ont un weight de 0 par dťfaut.
Les routeurs disposant d'un weight le plus haut sont prťfťres lors de la sťlection d'une route vers la mÍme destination, quand le choix existe.
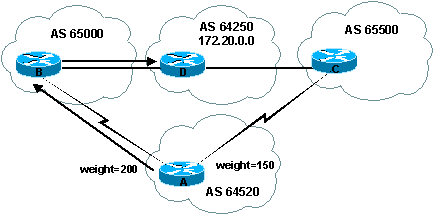
Dans cet exemple on voit bien que le routeur A choisiera de
passer par le routeur B pur aller en D, influencer qu'il est par le weight de
200, supťrieur au weight de 150 qui l'aurait fait envoyer se ballader du cŰtť de
C.
Ce type de mťtrique est un mťtrique ŗ la source, il n'est donc pas
nťcessaire de le forwarder ni en IBGP ni en EBGP.
3. La synchronistaion
Il existe un rŰle de synchronistaion: ne pas utiliser ou avertir ŗ un neighbor externe, une route apprise par IBGP, tant qu'une route correspondante n'est pas apprise par un IGP (OSPF, EIGRP Ö)
Tant que l'ensemble des routeurs d'un AS ne connaissent pas
une route apprise par IGP, celle-ci ne peut Ítre transmise par BGP vers un AS
externe.
Cette rŤgle est lŗ pour s'assuer de la consitance des informations
au travers des AS.
De plus elle prťvient la formation de trous (black holes)
ŗ l'intťrieur mÍme de l'AS.
Il est plus prudent de stopper la synchronistaion
quand tous les routeurs d'un AS tournent BGP.
Dans cet exemple, si la synchronisation est on (dťfaut):
- Les routeurs A, C et D ni n'utiliseront ni avertiront la route 172.16.0.0, tant qu'ils ne recervront pas la route correspondante par un IGP.
- Le routeur E n'entendra pas parler de 172.16.0.0
Si la synchronisatain est passťe en off:
- Les routeur A, C et D peuvent utiliser et avertir la route 172.16.0.0, apprise par IBGP. Le routeur E va entendre parler de la route 172.16.0.0
- Si le routeur E envoie du traffic pout 172.16.0.0, les routeurs A,C et D routeront correctement le traffic.
4. Les opťrations BGP
BGP dťfinit les types de messages suivants:
- Open qui inclue hold time et BGP ID
- Keepalive
- Update, informations pour un seul path seulement mais peut inclure plusieurs rťseaux. et inclue les attributs de path et les rťseaux.
- Notification, quand une erreur est dťtectťe, quand une connexion BGP close aprŤs envoi.
Les peers vont initialement ťchanger la table de routage
complŤte. Par la suite, seuls les updates seront envoyťs sosu forme d'updates
incrťmentaux. Les paquets keepalives sont envoyťs pour s'assurer de la connexion
entre les 2 peers.
AprŤs qu'une session TCP soit ťtablie, le 1į message
envoyť est un open. Si le message open est aceptť, un message keepalive de
confirmation de l'ouverture de a session est envoyť en retour. Une fois que le
message open est acceptť et que les updates et les keepalives sont ťtablis, les
messages de notifications peuvent Ítre ťchangťs.
Un open message inclut les
informations suivantes:
hold-time, le temps max entre 2 keepalives ou entre 2
updates. Quand un routeur reÁoit open message, le routeur calcule la valeur du
hold-time timer en utilisant la plus petite des valeurs du hold time local et de
celui reÁu dans le message open.
BGP router ID, 32 bits. L'identifier BGP est
un adresse IP assignťe au routeur et dťterminťe au dťmarrage. L'ID BGP est
sťlectionnťe de la mÍme maniŤre qu'OSPF, c'est l'adresse IP la plus haute des
adresses actives, ŗ moins qu'une adresses de loopback ne soit prťsente. Dans ce
dernier cas c'est l'adresse IP la plus haute des interface loopback qui sera
sťlectionnťe.
BGP n'utilise pas de protocole de transport spťcifique pour les
keepalives, mais utilise uniquement la mťcanique TCP en envoyant des messages
qui ne contiennent que le header.
Un update message ne contient que des
informations ŗ propos d'un path, de multiples paths nťcessitent de multiples
messages.
Tous les attributs du message concernent uniquement ce path et les
rťseau sont ceux qui peuvent Ítre utilisť pour le joindre. U message update
contient les champs suivants:
withdrawn routes, la liste des prťfixes IP pour
les routes qui sont withdrawn from service, if any.
path attributes, qui sont
l'AS-path, original, local preference. Chaque path attribute inclus le type, la
longeur et la valeur. Le type consiste du flag suivi du type code.
network
layer reachability information, la liste des adresses IP qui peuvent Ítre
jointes par ce path
Un message de notification est envoyť quand une erreur
est dťtectťe, la connexion BGP est close immťdiatement. Les messages de
notification incluent le code erreur et le subcode erreur ainsi que les donnťes
relatives ŗ cette erreur.
4.1. Le process de sťlection et de dťcision de routage
En considťrant seulement des routes synchronisťes sans boucles dans les AS et un next-hop valide, alors le choix se porte en prioritť sur:
- le weight le plus haut (local)
- la prťference locale la plus haute (globale dans les AS)
- la preferred route originaire du routeur local
- le preferred shortest AS-path
- preffered lowest origin code (IGP < EGP < incomplete)
- preferred MED le plus bas (from other AS)
- prefer EBGP path over IBGP path
- prefer the path through the closest IGP neighbor
- prefer oldest route for EBGP path
- prefer the path with the lowest neighbor BGP router ID
- prefer path with the lowest neighbor IP address
CIDR est un mťcanisme pour faire face ŗ la perte oppressive
d'adresses IP ainsi qu'ŗ l'augmentation de la taille des tables de
routage.
L'idťe est que des blocs d'adresses C peuvent Ítre combinťs ou
agrťgťs afin de crťer une plage plus large d'adresss IP.
Les anciennes
versions de BGP ne supportaient pas CIDR. BGP-4 dispose d'un support de
CIDR:
- Les messages updates de BGP supportent ŗ la fois le prťfixe et la longeur du prťfixe.
- Les adresses peuvent Ítre agrťgťes quand elles sont averties par un routeur BGP.
- L'attribut de l'AS-path peut inclure une list d'AS ŗ travers lesquels passent toutes les routes agrťgťes.
Il existe 2 attributs BGP relatifs ŗ l'agrťgation de
routes:
le well-known discretionary attribute: atomic aggregate, qui informe
l'AS voisin que le routeur d'origine a agrťger les routes.
l'attribut
optionel et transitif aggregator (le retour) spťcifie le BGP router ID et l'AS
number du routeur qui rťalise l'agrťgation de routes.
Par dťfaut, la route agrťgťe sera avertie comme provenant del 'AS d'oý est rťalisť l'agrťgation et qui aura l'attribut atomic positionnť. Les AS des routes non agrťgťes ne sont pas listťs. Le routeur peut Ítre configurť pour inclure la liste des AS contenus dans l'ensemble des paths qui sont summarizťs.
Les communautťs de BGP
|
Communautť |
Description |
|
Internet |
Demande au routeur d'anoncer cette route ŗ tous les IBGP et EBGP peers |
|
Local-AS |
Demande au routeur de ne pas anoncer cette route aux seuls IBGP peers |
|
no-advertise |
Indique au routeur de ne pas anoncer cette route ŗ tout IBGP ou EBGP peer. |
|
no-export |
Indique au routeur de ne pas anoncer cette route ŗ n'importe quel EBGP peer. |
5. La configurationde BGP
- Dťfinir un template avec des paramŤtres ajustťs pour un groupe de neighbors plutŰt que par routeurs individuels.
- Utile quand plusieurs neighbors possŤdent les mÍme outbound policies.
- Les membres peuvent avoir une inbound policy diffťrente.
- Les updates sont gťnťrťs une fois par peer group
- simplification de la configuration
Les routeurs BGP sont souvent configurťs ŗ l'aide de la mÍme
update policy (les mÍme filtres appliquťs par ex.)
Sur des routeurs Cisco,
les routeurs neighbors ces routeurs peuvent Ítre regrupťs en peer groups pour
simplifier la configuration.
Les membres d'un groupes hťritent des mÍmes
options de configuration. Les membres peuvent Ítre configurťs pour outrepasser
ces options ŗ condition que ces options n'affectent pas les updates en sortie
(outbound).
Les updates ne sont gťnťrťs qu'une seule fois pour le groupe.
router(config)# router bgp nį_autonomous-system --> autorise BGP
router(config-router)#
neighbor {ip-address|peer-group-name} remote-as autonomous-system
--> active une
session BGP avec un nouveau routeur, utilisť ŗ la fois avec IBGP et
EBGP
router(config-router)# network network-number
[mask network-mask] --> permet ŗ BGP d'avertir une route IGP si elle figure toujours
dans la table de routage. N'active pas le rpotocole sur une interface.
La commande network a une toute autre utilitť que dans les commandes des autres protocoles. La commande network ne sert pas ŗ indiquer sur quelle interface tourne le protocole, mais quel est le rťseu qui doit Ítre annnoncť ou injectť dans le nuage BGP.
5.1. 1į exemple
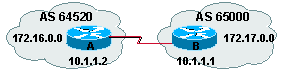
routerA(config)# router bgp 64520
routerA
(config-router)# neighbor 10.1.1.1 remote-as
65000
routerA(config-router)# network 172.16.0.0
routerB(config)# router bgp 65000
routerB
(config-router)# neighbor 10.1.1.2 remote-as
64520
routerB(config-router)# network 172.17.0.0
L'interface de la commande neighbor peut Ítre
une interface loopback.
Router(config-router)#
neighbor {ip-address|peer-group-name} next-hop-self
--> Force BGP ŗ utiliser la propre adrese IP d'un neighbor en
tant que next hop plutŰt que de permettre au protocole de choisir l'adresse du
next hop. On fixe l'adresse du next hop ŗ un point donnť. Cette commande permet
au sein d'un AS gťrť par IBGP de modifier le next-hop, qui est en gťnťral le
routeur externe.
Router(config-router)# no synchronisation
--> Dťsactive la synchronisation de BGP afin que le routeur
annonce les routes dans BGP avant de les apprendre par un IGP. Cette commande
est utilisťe quand un trafic provenant d'un autre AS ne doit pas passer au
travers de l'AS propre, ou si tous les routeurs de l'AS tournent BGP.
La
dťsactivation de la synchronisation permet de transporter moins de routes au
travers de l'IGP et permet ŗ BGP de converger plus rapidement.
Router(config-router)# aggregate-address ip-address mask [summary-only][as-set]
- Crťe une entrťe summary dans la table BGP
- Utiliser l'option summary-only pour avertir la summary et pas les routes spťcifiques. D'autre part sans cette option BGP continue d'envoyer les subnets.
- Ajouter l'option as-set pour inclure une liste de tous les 1es AS membres que les routes les plus spťcifiques doivent emprunter. Si l'option n'est pas prťcisťe, BGPnmentionne tous les 1es AS de tous les subnets, alors qu'avec cette option BGP ne mentionne que les subnets appris manuellement.
Router(config-router)# clear ip bgp {*|address} [soft[in|out]] --> resette les connexions BGP, ŗ utiliser aprŤs un changement de configuration de BGP.
N Le reset de BGP
va interrompre le routage. En effet pendant une Ĺ ŗ 1 heure, le routeur ne va
travailler qu'a a reconstruction de sa database et il ferme toutes les
connexions tcp.
! clear ip
route * va effacer la table de routage sans effacer la database
! clear ip bgp soft ne fait pas un reset
complet de ses connexions TCP. Le routeur gťnťŤre de nouvelles updates en entrťe
sans casser les sessions tcp. Cependant le routeur local conserve une copie de
tous les updates sans modifications, sans mÍme s'assurer que sa propre policy
peut les accepter ou pas. Ce process consume ťnormťment de mťmoire et doit Ítre
ťviter le plus possible. Outbound BGP soft n'est, quant ŗ lui, pas consomateur
d'un excťdent de mťmoire. Pour qu'une nouvelle policy prenne effet, il convient
d'utiliser la commande outbound.
5.2. 2į exemple BGP
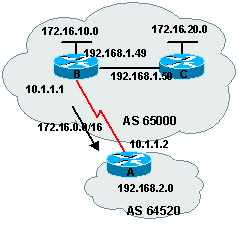
routerB(config)# router bgp 65000
routerB(config-router)# neighbor 10.1.1.2 remote-as
64520
routerB(config-router)# neighbor 192.168.1.50 remote-as
65000
routerB(config-router)# network 172.16.0.0 mask
255.255.255.0
routerB(config-router)# network 192.168.1.0 mask
255.255.255.0
routerB(config-router)# no
synchronization
routerB(config-router)# neighbor 192.168.1.50
next-hop-self
routerB(config-router)# aggregate-address 172.16.0.0
255.255.0.0 summary-only
Les 2 premiŤres commandes ťtablissent BGP que le routeur B
possŤde 2 voisins: routeur A dans AS 64520 et routeur C dans l'AS 65000.
Si
le routeur C annonce 172.16.20.0 dans BGP, le routeur B recevra cette route mais
ne la passera au routeur A jusqu'ŗ ce que la commande no synchronisation ne soit
rajoutťe sur les 2 routeurs B et C, puisqu'il n'y a pas d'IGP qui tourne dans
l'AS. Cette comande peut Ítre employťe dans ce cas puisque seul BGP tourne dans
'AS.
La commande clear ip bgp * devra Ítre lancťe sur les 2 routeurs B et C
afin de resetter les connexions TCP aprŤs que la synchronisation ait ťtť
arrÍtťe.
Par dťfaut le routeur B passe les annonces au routeur C provenant du
routeur A, ŗ propos du rťseau 192.168.2.0 avec l'adresse de next-hop ŗ 10.1.1.2.
Cependant, le routeur C ne connaÓt rien de l'adresse 10.1.1.2 et donc il
n'installera pas la route dans sa table de routage. La commande neighbor
192.168.1.50 next-hop-self force le routeur B ŗ envoyer des avertissements au
routeur C avec sa propre adresse (routeur B) en tant que next-hop, ce qui permet
au routeur C de joindre 192.168.2.0.
Le routeur A aprend les 2 subnets
172.16.0.0 ainsi que 172.16.20.0. Cependant une fois que la commande
aggregate-adresse 172.16.0.0 255.255.0.0 summary-only n'est pas rajoutťe au
routeur B, celui-ci summarize les subnets et n'enverra uniquement 172.16.0.0/17
au routeur A.
5.3. La vťrification de BGP
router# show ip bgp
[summary|neighbors]
show ip bgp
summary Ť affiche l'ťtat des connexions bgp
show ip bgp
summary Ť affiche les informations ŗ propos des connexions TCp et BGP
des voisins
router# debug ip bgp
6. BGP split horizon
Les routes apprises par IBGP ne sont jamais propagťes sur
d'autres peers IBGP. La consťquence est que IBGP doit Ítre full-meshed, tous les
routeurs doivent possťder une connexion TCP entre eux.
Le rťsultat est que
dans un AS, si tous les routeurs possŤdent une connexion TCp avec chacun
des autres routeurs on arrive ŗ n(n-1)/2 connexions TCP. De plus le trafic que
reprťsente une connexion de chaque routeurs avec tous les routeurs du nuage de
l'AS, est ťnorme. La soluton consiste ŗ adopter des routes reflectors
7. Les routes reflectors
Un route reflector est un routeur qui modifie le rŰle de BGP split horizon en autorisant le routeur configurť en route reflector de propager les routes apprises par IBGP aux autres peers. Cette approche diminue le nombre de sessions TCP dans l'AS et rťduit donc le trafic associť.
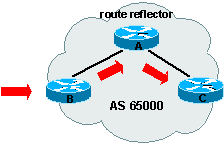
Les routess reflectors rťsolvent les problŤmes liťs ŗ IBGP et
le full-meshed, de ce fait est utilsť par les ISP quand le nombre de leurs
routeurs internes est grand.
L'envoi des paquets n'en n'est pas affectť, on
peut trouver plusieurs routes reflectors pour assurer la redondance. On peut
aussi trouver plusieurs niveaux de route reflectors. Les peers normaux peuvent
coexister et la migration est simple.
7.1. La terminologie des routes reflectors:
- route reflector: un routeur qui est autorisť ŗ reflťter les routes apprises via IBGP par d'autres peers IBGP. Le route reflector n'aura que de partielles connexions avec les autres routeurs qui sont appelťs clients. Le peering entre les clients n'est pas nťcessaire puique le route reflector va passer les avertissemensts antre les clients.
- cluster: c'est la combinaison des routes reflectors.
- nonclient: Les IBGP peers d'un route reflector qui ne sont pas clients.
- Originator-D: est un attriut optionel nontransitif de BGP qui est crťť par le route reflector. Cet attribut transporte le router-ID du routeur originel d'une route dans l'AS.
- cluster-id est lŗ pour distinguer plusieurs cluster qui agissent en redondance dans l'AS.
7.2. Le design des routes reflectors
Il convien t de diviser l'AS en plusieurs clusters, et
disposer d'un route reflector et de peu de clients dans un cluster.
Les
routes reflectors sont fully-meshed avec IBGP
Il convient d'utiliser
plusieurs IGP pour transporter les informations de next-hop ainsi que les routes
locales.
A l'implantation de routes reflectors il convient de se poser
certaines questions:
quels sont les ruteurs qui vont devenir des routes
reflectors ? Il faut suivre la topolgie physique ce qui garantiera que les
paquets n'en seront pas affectťs.
Il convient de configurer un route
reflector ŗ la fois, ce qui ťlimine la redondance de sessions IBGP et de placer
un route reflector par cluster.
7.3. Les opťrations des routes reflectors
Les reflectors reÁoivent des updates des clients et des
nonclients.
Si l'update provient d'un client, elle sera reflťchie aux client
et nonclients ŗ l'exception de l'originator.
Si l'update provient d'un
nonclient, elle sera rťflťchie aux seuls clients.
Si l'update provient d'un
peer EBGP, elle sera rťflťchie aux clients et nonclients.
7.4. La configuration des routes reflectors
router(config-router)# neighbor
ip-address route-reflector-client
La commande sert ŗ configurer
le routeur en tant que route reflector et cnfigure un neighbor spťcifique en
tant que client. En fait on ne dispose pas de commande spťcifique pour dire que
le routeur est route-reflector, mais uniquement d'une commande qui prťcise oý se
situent les clients du route reflector.
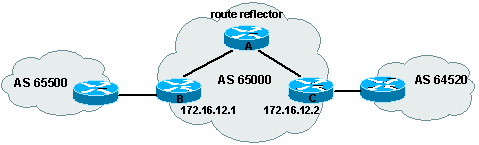
routerA(config)# router bgp
65000
routerA(config-router)# neighbor 172.16.12.1 remote-as
65000
routerA(config-router)# neighbor
172.16.12.1 route-reflector-client
routerA(config-router)# neighbor 172.16.12.2 remote-as
65000
routerA(config-router)# neighbor 172.16.12.2
route-reflector-client
La vťrification de la configuration des route reflectors est
particuliŤre. En effet, on ne voit pas qu'un routeur et route reflector, mais
uniquement qu'il possŤde des clients par la commande show ip bgp
neighbors.
La redistribution :
Si des routes internes ŗ un AS doivent Ítre
annoncťes, la redistribution doit Ítre configurťe dans BGP. Dans ce cas il
existe 3 mťthodes de redistribution en utilisant la commande network :
- une redistribution de routes
- une redistribution de routes statiques dans BGP
- une redistribution manuelle des routes de la table de routage
8. Policy control
Pour restreindre les informations de routage vers ou depuis les neighbors, on peut utilser:
- distribution lists (en utilisant des access-lists)
- prefix list
- route map
8.1. Prefix list
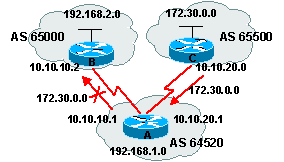
Le routeur A peut interdire aux updates 172.30.0.0 d'aller
vers AS65000
Les prefix list peuvent Ítre utilisťe comme alternative aux
access-list dans la plupart des commande de filtrage de BGP. Les avantages
sont:
- une performance significativemet accrue
- un support pour les modifications incrťmentales en introduisant les sequence number
- plus de flexibilitť
- des commandes plus agrťables ŗ taper !! (est-ce bien sŻr ?)
Le filtrage avec les prefix listes:
- correspondance entre les prťfixes de routes et les prefixes das la liste.
- une liste de prefixes vide autorise toutes les routes
- permit=use route
- le routeur commence la recherche d'occurrence au dťbut de laliste avec le sequence number le plus bas.
- Quand il y a correspondance, le reste de la liste est ignorťe.
- Un implicite deny termine la liste de prťfixes.
8.2. Les options de redistribution
Les commandes distance et default-metric, permttent de
s'assurer que la redistribution entre RIP et OSPF s'effectuera sans boucles. Ces
commandes associťes permettent de sťlectioner un path sub-optimal.
Quand OSPF
est redistribuť au travers d'EIGRP, la commande default-metric permet de donner
un mťtrique ŗ une route dirctement connectťe par un ASBR.
Quand un routeur
rťcupŤre une route depuis un autre AS de nature diffťrente, il lui affecte un
seed metric.sera incrťmentť au fur et ŗ mesure de sa propagation au sein du
nouvel AS. Cependanr quand les 2 routeurs tournent avec chacun un AS diffťrent
et un protocole de routage diffťrent, le mťtrique ne pourra Ítre affectť de
maniŤre automatique.
De plus si il existe dťjŗ une route identique conne par
le protocole de routage local, il est fortement conseillť d'affeter un mťtrique
plus haut pour la route injectťe de faÁon ŗ ťviter les boucles.