OSPF est un protocole de type link-state. Comme tout bon
protocole il assume les 2 fonctons de base, path selection et path forwarding. A
l’heure actuelle OSPF se décline en V2. OSPF est un protocole IGP (Interior
Gateway Protocol) ce qui veut dire qu’il distribue ses informations au travers
de routeurs appartenant au męme systčme autonome.
OSPF est classless. Sa
conergance oscille entre 6 et 45 sec. Lors d’un changement, il transmet
uniquement le changement et non pas l’entičreté de la table de routage.
Ces
atouts sont :
OSPF utilise le protocol number 89 d’IP, ce qui veut dire qu’il utilise ses propres techniques de couches hautes, sans passer par TCP.
Interface : la connexion entre le routeur et l’un
des réseaux attachés (parfois appelé link)
Link state : l’état
d’un lien entre 2 routeurs, cad l’interface et la relation au routeur voisin.
Les link states sont envoyés au travers de paquets spéciaux : les LSA (Link
State Advertisements).
Cost : La valeur associée ŕ un lien, le
cost est basé sur
Autonomous system : un groupe de
routeurs qui s’échangent des informations et qui utilisent un protocole de
routage en commun.
Area : -
Neighbors : 2
routeurs qui ont des interfaces en commun sont voisins.
Hello :
le systčme de paquets qui sont envoyés entre les routeurs et qui émulent les
keepalives. Ce protocole permet d’établir et de maintenir les relations de bons
voisinage.
Neighborship database : LA liste de tous les voisins
avec qui sont établis des relations bidirectionelles.
Link-state
database : appelée aussi topological database, une liste des entrées
link-state de tous les routeurs dans le réseau. Tous les routeurs d’un systčme
ont la męme link-state database.
Routing table : ou forwarding
table, elle est générée par SPF (appelé aussi Dijkstra algorithm)
Il existe 3 topologies pour OSPF :
Broadcast
Multiaccess —> typiquement un LAN
Point
to Point —> un lien entre 2 routeurs
NBMA
—> plusieurs
routeurs reliés au travers d’un réseau qui ne supporte pas le broadcast
NBMA=
Non Broadcast Multiple Access
OSPF est dépendant du status des liens entre 2
routeurs.
La 1° étape est de reconnaître et de se faire reconnaître par ses
voisins.
Pour cela OSPF utilise le hello protocole. Ce protocole sert ŕ
établir et maintenir les relations de bons voisinage. Il s’assure que les
relations entre voisins sont bidirectionnelles.
Les hello packet sont
transmis réguličrement sur l’ensemble des interfaces qui font tourner OSPF.
L’adresse utilisée est une adresse multicast (n’oublions pas que nous nous
trouvons en LAN) : 224.0.0.5 (AllSpfRouters)
Les hello packet
contiennent :
|
Router ID |
32 bits- par défaut l’adresse IP la plus haute |
|
Hello
interval |
10 sec. |
|
Dead interval |
4xhello interval = 40 sec sur un réseau multiaccess |
|
neighbors |
Quand une relation bidirectionnelle est établie |
|
Area-ID |
|
|
Router
priority |
8 bits pour la sélection du DR et du BDR |
|
DR & BDR IP
address |
|
|
Authentication
password |
|
|
Stub area
flag |
1 bit |
Le DR est le point central du réseau en ce qui concerne
l’échange des link-state informations.
Le BDR est un backup du DR.
Une
élection ŕ lieu entre les routeurs pour savoir qui est le DR et le BDR, elle se
fait en 1° lieu sur base de la priorité puis sur base de la plus grande adresse
IP de chaque routeur, sauf en cas d’utilisation d’une interface loopback qui
reste prioritaire.
OSPF privilčgie la stabilité, c’est pourquoi un routeur
qui rentre sur le réseau aprčs qu’ une éléction ait déjŕ désigné un DR et un
BDR, ne peut devenir DR męme si ce routeur dispose d’une priorité plus
haute.
Une fois le DR et le BDR élus, les routeurs n’ établissent des
relations adjacencies qu’ avec le DR et le BDR, les LSA ne sont envoyés qu’ au
DR et au BDR.
1° le routeur qui possčde la plus haute priorité est le
DR.
2° Le routeur avec la seconde plus haute priorité est le BDR.
3° La
valeur par défaut de la priorité d’une interface OSPF est 1. En cas dégalité,
c’est le router ID qui est employé. Normalement le router ID est basé sur la
plus haute adresse IP des interfaces, on utilise souvent une interface de type
loopback pour contôler cette valeur.
4° un routeur qui possčde une priorité
de 0 est inéligible.
5° si un routeur qui possčde la plus haute priorité est
rajouté au réseau aprčs l’élection, rien ne change.
La 1° procédure est l’exchange process qui se décompose de la
maničre suivante :
1. Le routeur A démarre en down state, il n’a
pas encore échangé d’informations avec les autres routeurs.
Il envoie des
hellos packets ŕ travers toutes ses interfaces qui participent ŕ OSPF sur
224.0.0.5 (AllSpfRouters)
3. Chaque routeur qui reçoit un hello packet renvoie un unicast
reply hello packet. Le champ neighbor contient la liste compčte des neighbors y
compris celle du routeur A, issu du step 1.
4. Two way state :
quand le routeur A reçoit les paquets hello en retour et pour chaque paquet qui
contient A, A rajoute les neighbors ŕ sa propre table. Du point de vue de A, une
communication bidirectionelle s’est établit pour chaque routeur tournant OSPF
puisque il y a eu envoi de l’ID du routeur A puis récupération de cette ID au
travers du paquet reçu.
5. Le routeur détermine qui est le DR et le
BDR.
6. périodiquement, toutes les 10 sec. par défaut, les routeurs du męme
réseau s’échangent des hellos packets pour s’assurer que la communication
fonctionne toujours. Ces hellos packets incluent les DR et BDR ainsi que la
liste des routeurs dont les hellos packets ont été reçus par le routeur, oů
reçus signifie que le routeur ŕ reconnu sa propre adresse dans les hellos
packets.
Une fois que DR et BDR sont élus, les routeurs sont
considérés dans l’exstart state et son pręts ŕ découvrir les informations
de link-state de l’interréseau afin de construire leur propre database.
Le
process de découverte de routes se nomme exchange protocol et sert ŕ ce
que les routeurs aient des communications en full state. La 1° étape de ce
protocole consiste ŕ ce que le DR et le BDR établissent des adjacencies avec
chacun des routeurs.
La description de l’exchange protocol :
1. Dans
l’exstart state, DR et BDR ont établis des adjacencies avec chaque routeur dans
le réseau. Durant ce process une relation master-slave s’est instaurée entre
chaque routeur et son DR et BDR. Le routeur qui possčde la plus haute ID est le
master.
! Les
informations link-state sont échangées et synchroniusées uniquement entre DR et
BDR et le routeurs avec lesquels sont établis des relations d’adjacencies.
2.
Les routeurs master et slaves s’échangent des description de database ŕ l’aide
de DBD ou DDP (Database Description Packet).
Un DBD incluse des informations
sur les entrées de LSA qui apparaissent dans la table du master.
Les entrées
traitent soit un lien soit un réseau et comprend un sequence number et le cost
du link.
3. Quand le slave reçoit ses DBD il renvoie un accusé de réception
en renvoyant le sequence number de l’entrée du link-state. Puis il compare les
informations reçues et celles qu’il possčde déjŕ. Si le DBD comporte des entrées
plus récentes que celles qu’il possčde déjŕ, le slave envoie un link-state
request LSR, on est dans le loading state.
Le master répond avec
l’information complčte correspondant ŕ l’entrée dans un link state update LSU.
Le slave renverra le LSAck au master pour confirmer la réception.
4. Chaque
routeur ajoute la nouvelle entrée link state dans leurs database.
5. Une fois
que toutes les LSR sont satisfaites, les roueurs adjacents sont considérés comme
synchronisés et dans un état full state . Les routeurs doivent ętre en état full
state avant de router le trafic.
Récapitulatif des états :
|
OSPF Neighbor
state |
Description |
|
Down |
Le routeur ne reçoit ni n’envoie de Hellos |
|
Init |
Le routeur vient de recevoir des Hellos depuis un routeur joint, et ŕ rajouter le RouterID du routeru joint ŕ sa propre table d’adjacency. |
|
Two ways |
Le routeur ŕ reçu des Hellos depuis un routeur joint et qui contiennent son propre RouterID. |
|
Exstart |
Le routeur établi une adjacency avec le DR/BDR, établit une relation maître/élčve et échange sa Database Description (DD) avec les routeurs adjacents. |
|
Exchange |
Le routeur utilise sa DD et ses LSR packets pour échanger sa link-state-database avec le routeur adjacent. |
|
Loading |
Le routeur échange des paquets LSR avec le routeur adjacent, et demande la liste de tous les LSA récents qui ont été rajoutés ŕ chaque link state database |
|
Full |
Le routeur est complčtement adjacent avec les routeurs voisins, et détient une information link state courante pour les 2 routeurs |
Les protocoles de type link state utilisent un cost basé sur
la BW.
OSPF utilise SPF (Dijkstra algorithm) qui construit la table de
routage step by step en ajoutant le total des coűts entre la racine (root=le
routeur lui męme) et chaque destination du réseau.
Dans le cas oů il existe
plusieurs chemins de coűts identiques pour une destination, le routeur réalise
du load balancing sur un maximum de 6 routes.
De temps en temps un lien fait
du flapping, il passe de l’état up ŕ l’état down de maničre successive. Pour
éviter une trop grande charge réseau et cpu résultant du calcul SPF, OSPF
féclenche un timer en dessous duquel il ne prnd pas en compte les changements
sur un lien, spf-delay qui est de 5 sec. ainsi que le spf-holdtime de 10 sec qui
interdit de reclaculer SPF durant cette période.
Un routeur notifie tous les OSPF DR sur 224.0.0.6
Le Dr
notifie tous les "other" sur 224.0.0.5
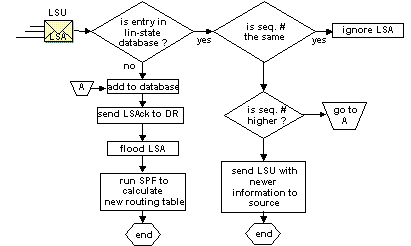
1. le routeur A capte un changement,
il multicast un LSU vers 224.0.0.6 (AllOspfDr) (et all ospf
bdr). Un LSU contient plusieurs LSA.
2. Le DR accuse réception du changement
et floode le LSU sur tous les autres routeurs en 224.0.0.5 (AllOspfRouters).
Aprčs réception du LSU chaque routeur répond au DR avec un LSAck. Chaque LSA
possčde un accusé de réception unitaire.
3. Si un routeur est connecté ŕ u
autre réseau, il floode le LSU ŕ son DR ou ŕ son adjacent router si il s’agit
d’un réseau point ŕ point.
4. En utilisant le LSU qui comprend le LSA qui a
changé, le routeur fait tourner SPF et remet sa table de routage ŕ jour.
Un
résumé des entrées individuelles des link state sont envoyées environ toutes les
30 min.
Chaque entrée de LSA est soumise ŕ un age dont la valeur par défaut
est de 30 min.
! Les LSA dont nous
discuttons ne forment qu’une partie de la famille des LSA.
Il s’agit de LSA
qui décrivent un lien et son état ainsi que de LSA réseau envoyés par le
DR.
Les LSA réseaux décrivent tous les routeurs attachés ŕ un segment
multiaccess.
Par la suite nous décriverons d’autres types de lSA.
Un réseau point ŕ point ne comporte qu’une paire de routeurs,
ex une ligne T1
Dans un réseau point ŕ point, les routeurs détectent
dynamiquement leurs voisins en envoyant des helllos packets sur le 224.0.0.5
(AllSpfrRouters). Dans tous les cas les routeurs deviennent adjacents
automatiquement et la notion de DR et de BDR n’esxiste plus.
Hello interval = 10 sec.
Dead interval = 40
sec.
Dans un réseau NBMA, la nature nonbraodcast du réseau pose de
nombreux problčmes.
Un réseau NBMA supporte de nombreux routeurs (plus de 2)
et ne possčdents donc aucune possibilité de tranmettre des broadcasts. C’est le
cas pour les réseaux Frame relay, ATM, X25.
Hello interval =
30 sec.
Dead interval = 120 sec.
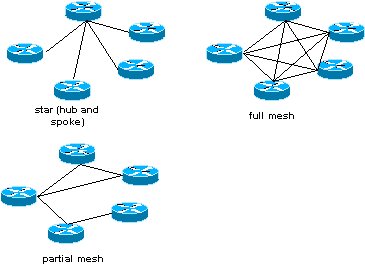
Star topologie : la plus fréquente des topologies en
Frame realay, un site central qui connecte les sites distants.
C’est la
topologie la moins chčre puisque c’est elle qui requiert le moins de PVC. Dans
cette topologie le routeur central possčde une connexion multipoint en utilisant
une interface pour interconnecter de multiples PVC.
Full
mesh : tous les routeurs possčdent un circuit virtuel avec tous les
routeurs de réseau. C’est la topologie la plus onéreuse, mais elle dispose de
liens redondants.
Partial mesh : tous les sites ne
disposent pas de connexion avec l’ensemble des routeurs du
réseau.
Dans un réseau Frame Relay par défaut, les routing
updates ne sont pas répliqués entre les routeurs.
La sélection du DR dans les
topologies NBMA :
OSPF considčre un réseau NBMA comme un réseau
brodcast. DR et BDR nécessitent de posséder une connexion physique avec tous les
autres routeurs. De plus le Dr et le BDR ont besion de la liste de l’ensemble
des neighbors.
|
Mode |
Type |
Adjacency |
DR/BDR |
subnet |
topologie |
|
NBMA |
RFC |
conf. manuelle |
élection |
le męme |
full mesh |
|
Broadcast |
Cisco |
automatique |
élection |
le męme |
full mesh |
|
Point to
multipoint |
RFC |
automatique |
no DR/BDR |
le męme |
partial mesh ou star |
|
Point to |
Cisco |
conf.
manuelle |
no DR/BDR |
le męme |
partial mesh ou star |
|
Point to
point |
Cisco |
automatique |
no DR/BDR |
différent pour chaque subinterface |
partial mesh ou star avec subinterface |
|
|
|
|
|
|
|
On retiendra :
Broadcast et NBMA : élection d’un
DR/BDR
Point ŕ … : pas de DR/BDR
Nonbradcast (NBMA
et point to multipoint nonbraodcast) : configuration manuelle des
adjacencies.
Si le DR et LE BDR ne sont pas dans une toplogie full mesh,
il convient de les sélectionner manuellement.
NBMA, dans le cas oů le nombre
de voisins n’est pas énorme, est la meilleure solution sur un réseau
nonbroadcast multiaccess en terme de taille de database de link state ainsi
qu’en terme de charge de trafic du protocole de routage.
On rencontre ce type
d’accčs sur une topologie full mesh composée soit de liens ATM utilisant des SVC
soit de liens FR reliés par le biais de subinterfaces.
Ce type d’approche fonctionne sur des topologies partial mesh
ou star. Dans le mode point to multipoint, OSPF traite l’ensemble des routeurs
comme ayant une connexion de mode point ŕ point. De ce fait il n’existe pas
d’élection de DR/BDR.
En mode point to multipoint, des LSA spéciaux sont
utilisés qui décrivent la connectivité des routeurs voisins.
Le mode point to
multipoint réduit le nombre de PVC dans les réseaux larges.. De plus le nombre
de routeurs et de liens sont moins importants que dans le mode full mesh, ce qui
se traduit par une réduction du nombre de voisins dans les tables.
Ce mode
Il s’agit d’un mode spécifiquement Cisco oů les neighbors sont définis manuellment et oů on peut redéfinir le cost des liens. La RFC point to multipoint a été développée pour des VC qui supportent le multicast ou le broadcast et qui autorise la découverte dynamique des neighbors. Cependant certaines technologies utilisées dans les configurations point ŕ multipoint utilisent des médias nonbroadcast comme IP sur ATM et ne peuvent dons pas utiliser le mode point to multipoint RFC.
Le broadcast mode reflčte une autre approche : tous les routeurs se connaissent. Les interfaces vont ętre passée dans un mode broadcast et se croire ŕ l’intérieur d’un LAN. Dans ce cas il y aura élection de DR/BDR.
Le mode point to point est utilisé uniquemant en présence de
2 nodes connectés ŕ un réseau de type NBMA. Ce mode est utilisé typiquement avec
des subinterfaces point to point. Chaque connexion point ŕ point utulise son
propre subnet. Une adjacency est formée sans élection de
DR/BDR.
On utilise trčs souvent les subinterfaces dans
l’environnement NBMA. Une interface physique peut ętre splittée en de nombreuses
sous interfaces logiques appelée subinterfaces.
Les subinterfaces ont été
crées au départ comme réponse ŕ split horizon sur NBMA.
router(config)# interface serial number.subinterface_number multipoint | point-to-point
multipoint : tous les
routeurs sont dans le męme subnet.
point-to-point : chaque paire de
routeur point ŕ point se trouve dans le męme subnet.
! Quand OSPF tourne sur
des liens comportant das subinterfaces, il est souvent défini au niveau des
subinterfaces. De ce fait il ne sait pas détecter si le lien principal est en
défaut.
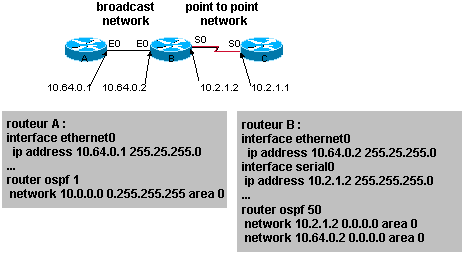
La commande network est extręment puissante. Elle permet de
préciser de maničre trčs fine ce qui sera traité par OSPF et ce qui ne le sera
pas.
Pa rla commande network on peut assigner soit un réseau complet
(0.255.255.255) soit une inetrface (0.0.0.0).
La commande network utilise la
notation de type wildcard mask.
Le process id (router ospf #) n’a pas grande
importance, il n’est lŕ que dans le cas ou plusieurs instances d’OSPF tourne sur
le męme routeur.
L’area id définit
Nous avons déjŕ vu que cette interface représentait un énorme
interęt dans le cas d’OSPF oů elle sera utilisée pour contrôler le router id. En
effet cette interface virtuelle ne tombe jamais, de plus elle est contrôlable.
On peut choisir de la diffuser oun pas. Dans le cas oů on publie cette adresse,
il est fort ŕ parier que celle-ci sera une adresse publique alors que dans le
cas oů on ne la publie pas, on pourra utiliser une adresse privée.
Création
de l’interface loopback :
router(config)# interface loopback
number
router(config-if)# ip addresse
@IP
router(config-if)# no shutdown
Puis on choisit d’annoncer ou
non cette interface au travers d’OSPF :
router(config)# router ospf
10
router(config)# network @IP_loopback 0.0.0.0 area #
Pour déterminer le
router id :
router# show ip ospf interface
Pour modifier la
priorité d’OSPF sur une interface :
router(config-if)#
ip ospf priority number
On peut modifier le cost d’un lien
pricipalement dans le cas d’une redistribution avec des routeurs non
Cisco.
router(config-if)# ip ospf cost
cost
10exp8/bandwidth
Ligne 56K —>
1785
T1— > 64
ethernet 10M
—>
10
T.R. 16M —>
6
Configuration d’une interface en mode NBMA :
Router(config-if)# ip ospf network
non-broadcast
Configuration d’une interface en mode
point-to-multipoint :
Router(config-if)# ip ospf
point-to-multipoint [non-broadcast]
Configuration d’une interface
en broadcast mode
Router(config-if)# ip ospf network
broadcast
Configuration d’une interface en mode
point-to-point
Router(config-if)# ip ospf network
point-to-point
Frame-Relay est un exemple de topologie muliaccess
nonbroadcast.
Les nuages NBMA peuvent ętre soit :
Les réseaux NBMA ne supportent pas par défaut les
broadcasts.
Parcequ’OSPF voit un NBMA comme un réseau capable de broadcast,
il convient de préter un soin attentif ŕ la configuration ŕ utiliser.
5 modes
existent pour configurer OSPF au travers d’un nuage FR.
|
Mode |
Subnet IP requis |
Neighbor adjacency-DR/BDR
election |
|
Broadcast |
1 |
Automatic adjacency, DR/BDR
élus |
|
NBMA |
1 |
Manuelle adjacency, DR/BDR élus |
|
Point-to-multipoint |
1 |
Automatic adjacency, DR/BDR non élus |
|
Point-to-multipoint-non-broadcast |
1 |
Manuelle adjacency, DR/BDR non élus |
|
Point-to-point |
subnet séparés pour chaque sous-interface |
Automatic adjacency, DR/BDR non élus |
Si on souhaite n’utiliser qu’un seul subnet dans le nuage, ne
pas configurer manuellement les neighbors et qu’il n’y ait pas d’élection de
DR/BDR, alors le mode point ŕ multipoint sur interfaces simples
convient.
Dans ce cas le mode broadcast mettrait en place une élection
DR/BDR., tandis que le mode point-to-point sur sous-interfaces ne mettrait pas
en action d’élection DR/BDR mais consommerait un subnet pour chaque Virtual
Circuit (VC) configuré.
Routeur(config)# interface serial0
Routeur(config-if)# ip address 10.1.1.1
255.255 .255.0
Routeur(config-if)# encapsulation
frame-relay
Routeur(config-if)# ip ospf network
non-broadcast
Routeur(config)# router ospf
1
Routeur(config-router)# network 10.1.1.0 0.0.0.255 area 0
Routeur(config-router)# neighbor
10.1.1.2
Routeur(config-router)# neighbor
10.1.1.3
Routeur(config-router)# neighbor 10.1.1.4
!neighbor ip-address priority priorité
poll-interval sec cost number
! la
commande neighbor est indispensable dans le mode NBMA.
!
nonbroadcast mode par défaut, la commande ip ospf network n’est pas
nécessaire.
Routeur(config)# interface serial0
Routeur(config-if)# ip address 10.1.1.1
255.255 .255.0
Routeur(config-if)# encapsulation
frame-relay
Routeur(config-if)# ip ospf network
point-to-multipoint
Routeur(config)# router ospf
1
Routeur(config-router)# network 10.1.1.0 0.0.0.255 area 0
! point-to-multipoint
non-broadcast a été introduit aprčs la version 11.3.
sans la précision
non-broadcast, le mode point-to-multipoint est considéré comme un réseau de type
broadcast, et le mode est du type RFC.
Avec la précision non-broadcast, le
réseau est considéré non broadcast et le mode est du type Cisco. Dans ce cas la
commande neighbor est requise.
Routeur(config)# interface
serial0
Routeur(config-if)# ip address 10.1.1.1
255.255 .255.0
Routeur(config-if)# encapsulation
frame-relay
Routeur(config-if)# ip ospf network
broadcast
Routeur(config)# router ospf
1
Routeur(config-router)# network 10.1.1.0 0.0.0.255 area 0
Routeur(config-router)# neighbor
10.1.1.2
Routeur(config-router)# neighbor
10.1.1.3
Routeur(config-router)# neighbor 1
0.1.1.4
Routeur(config)# interface serial0
Router(config-if)# no ip address
Router(config-if)#
interface serial0.1 point-to-point
Routeur(config-if)# ip address
10.1.1.1 255.255 .255.0
Routeur(config-if)# encapsulation frame-relay
interface-dlci 51
Router(config-if)# interface serial0.2
point-to-point
Routeur(config-if)# ip address 10.1.2.1
255.255 .255.0
Routeur(config-if)# encapsulation frame-relay
interface-dlci 52
Routeur(config)# router ospf
1
Routeur(config-router)# network 10.1.0.0 0.0.255.255 area
0
OSPF considčre chaque subinterface comme un interface physique
point-to-point
Les adjacencies sont automatiques.
Vérification des opérations OSPF
Router# show ip
protocols —> vérifie qu’OSPF est
configuré.
Router# show ip route —> indique toutes les routes
apprises par le routeur.
Router# show ip ospf interface
—> indique area ID et
informations d’adjacencies
Router# show ip ospf
—>
indique les timer et les statistiques d’OSPF
Router# show ip ospf neighbor
details —> indique les infos sur les
DR/BDR et neighbors.
Router# show ip ospf database
—>
indique la database link-state.
Router# clear ip route *
—> sans
commentaires
Router# debug ip osp fadj|events|flood|lsa-generation|
packet| retransmission|spf|tree
Router# show ip ospf
neighbor ŕ sur un réseau
point-to-point
Neighbor ID Pri
State Dead Time
Address Interface
192.168.0.13
1 2WAY/DROTHER
192.168.0.14
1 FULL/BDR
192.168.0.11
1 2WAY/DROTHER
192.168.0.12
1 FULL/DR
Router# show ip ospf neighbor ŕ
sur un réseau NBMA broadcast
Neighbor ID Pri
State Dead Time Address
Interface
192.168.0.12 1
FULL/DROTHER
192.168.0.13 0
FULL/DROTHER
192.168.0.11 1
FULL/BDR 00:00:56
10.1.1.1 Ethernet0
Dans ce cas l’état est full avec tout le monde.
On utilise
la commande neighbor sous la commande router ospf pour que les adjacencies
soient établies.
La commande a été passée depuis le routeur qui est DR
(192.168.0.14). Son neighbor est le BDR 192.168.0.11.
Le réseau est fully
meshed.
Quels sont les problčmes d’OSPF dans un réseau large :
L’idée est donc de subdiviser l’autonomous system en entités
plus petites : les zones ou area.
Les avantages de diviser le réseu en
area sont :
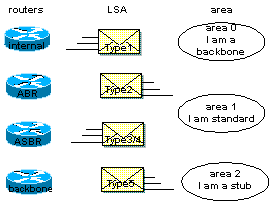
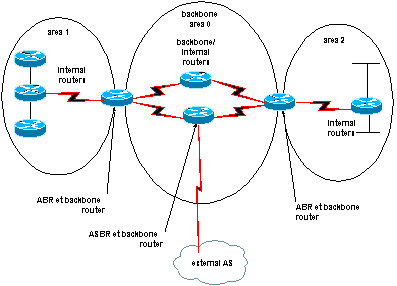
! Un routeur peut trčs
bien appartenir ŕ plusieurs types différents, par exemple si il interconnecte
l’area 0 et l’area 1 ainsi qu’un réseau non OSPF, il sera ABR et ASBR en męme
temps, lŕ !
! Un routeur peut
posséder plusieurs link-state database si il est connecté ŕ plusieurs areas. Les
routeurs qui appartiennent ŕ la męme area possčdent évidemment la męme
link-state database.
! Une link-state
database est synchronisée entre une paire de routeurs adjacents ou autrement dit
entre un routeur et son DR et son BDR.
type 1 (O)
č router link entry
type 2 (O)
č network link entry
type 3 et 4
(IA) č summary link entry
type 5
(E1/E2) č
AS external link entry
|
type |
link-state |
qui
génčre |
nom |
contenu |
destination |
|
1 |
router |
tous les routeurs |
O |
neighbor (pt ŕ
pt)
network number
(multiaccess) |
tous les routeurs de l’area |
|
2 |
network |
DR |
O |
liste des routeurs connectés |
tous les routeurs de l’area |
|
3 |
summary |
ABR |
IA |
résumés |
les areas connectées |
|
4 |
summary |
ASBR |
IA |
résumés |
les areas connectées |
|
5 |
external |
ASBR |
E1/E2 |
résumés |
tout le monde |
OSPF rquiert un minimum de une area : 0 pour le backbone. Les autres areas peuvent porter la numérotation quelles veulent y compris prendre la forme d’adresses IP.
Le cost d’une summary route est le plus petit cost d’une interarea route donnée + le cost du lien de l’ABR au backbone.
Le calcul d’une route externe dépend de la configuration de l’ASBR :
La sélection de la route s’opčre toujours sur la concordance
la plus exacte rencontrée dans la table de routage, par ex supposons que la
table de routage contienne les 3 adresses suivantes:172.16.64.0/18,
172.16.64.0/24,172.16.64.192/27 et que l’adresse de des tination est
172.16.64.205. DAns ce cas c’est le choix 3 qui sera sélectionné puisque c’est
cette adresse qui est la plus spécifique et proche de l’adresse de
destination.
Si aucune adresse ne correspond, il y aura génération d’un
message ICMP ŕ la source.
Les path types sont parcourus
dans un certain ordre :
1. Intra-area path
2.
Inter-area path
3. E1 external path
4. E2 external path
Si le paquet est ŕ destination d’un réseau ŕ l’intérieur
d’une area, le routeur envoie ce paquet directement sur le routeur
concerné.
Si le paquet est ŕ destination d’un réseau en dehors de l’area, il
devra suivre ce trajet :
Le process de flooding de LSUs au travers de multiples
areas
Les ABR sont responsbles de la génération des informations de routage
pour chaque area auquelles ils sont connectées. Les ABR floodent les
informations ŕ destination des autres areas de l’AS en utilisant le backbone
area.
3. Les summaries LSAs (type 3
et 4) sont placé dans des LSUs et ditribués au travers des inetrfaces des ABRs,
avec toutefois certaines exceptions :
Quand n ABR ou un ASBR reçoit des LSAs summaries, il les
ajoute ŕ sa propre link-state database et les floode au sein de l’area locale.
Les routeirs internes assimilent cette information dans leurs propres
databases.
Une fois que toous les routeurs ont reçus les routing updates, ils
divent les ajouter ŕ leur propres databases et recalculer SPF. L’ordre de
recalcul est le suivant :
1. Les routeurs calculent d’abord les paths ŕ
destination de leurs propres areas et rajoutent les entrées ŕ leurs propres
tables de routage. Ce sont les types 1 et 2 de LSAs.
2. Tous les routeurs
calculent ensuite le path vers les autres areas de l’AS. Ces paths sont les
interarea route entries et sont donc des lSAs 3 et 4. Si un routeur possčde une
interarea route vers une destination ainsi qu’une intraarea route vers la męme
destination, c’est l’intraarea route qui est conservée.
3. tous les routeurs
ŕ l’exception de ceux qui font parti d’une staub area, calculent le path vers
lexternal AS (type 5).
4. Quand un ABR ou un ASBR rçoit des
summaries LSAs ils les rajoutent ŕ leur propre database et les floodent dans
l’area locale. Puis les routeurs internes assimilent ces informations dans leurs
propres databases.
! Pour réduire le
nombre de routes qu’un routeur interne doit maintenir, il suffit de configurer
l’area en stub area.
Une fois que tous les routeurs ont reçus leurs routing
updates, ils les ajoutent ŕ leur link-state database et recalculent leurs
trables de routage. L’ordre utilisé pour calculer les paths est le
suivant :
1. Tous les routeurs calculent le path des destinations de
leur propre area et rajoutent les entrées ŕ la table de routage. Ce sont les
LSAs de type 1 et 2.
2. Puis tous les routeurs calculent les paths ŕ
destination d’autres areas dans l’internetwork. Ces paths sont des routes
onterarea et sont donc des LSAs de type 3 et 4. Si un routeur possčde une route
de type interarea et une route de type interarea pour la męme destination,
l’intraarea route sera celle qui sera conservée.
3. Tous les routeurs,
exceptés ceux qui se trouve dans une area stub ou totalement stubby, calculent
les paths vers les AS externes (type 5).
A ce point tous ls routeurs peuvent
communiquer avec l’ensemble des réseaux internes et externes (de l’AS)
connus.
OSPF dispose de certaines restrictions quand de nombreuses
areas sont configurées.
L’une des area doit ętre la backbone area (0) au
travers de laquelle transitet toutes les communications.
Toutes les areas
doivent donc ętre connectées ŕ la backbone area.
Dans certains cas, le seul
moyen de joindre la backbone area est d’emprunter une area existante. Dans ce
cas il n’y a pas de connexion directe, on utilise un virtual link qui permet de
joindre la backbone area.
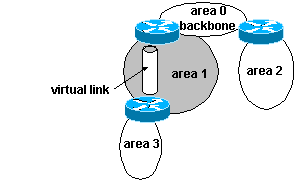
Quand les virtual links sont utilisés, il est nécéssaire de requérir un process spécial d’OSPF durant le calcul d’OSPF. En effet le véritable next-hop router doit ętre déterminé de telle façon que le cost exact puisse ętre utilisé.
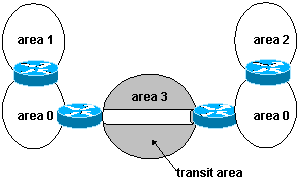
Les virtuals links servent ŕ :
La configuration d’un virtua-link :
1° configurer
OSPF
2° passer la commande virtual-link avec area qui est le nom de l’area de
transit et router-id qui est le router-id de destination (visualisable par la
commande show ip ospf interface)
router(config-router)#
area area_id virtual-link
router-id
Il n’existe pas de commande spécilae pour configurer un
routeur en ABR ou ASBR. Le routeur assume ce rôle par lui męme.
Les basiques
concernant la configuration d’ospf sont :
1. démarrer OSPF sur le
routeur
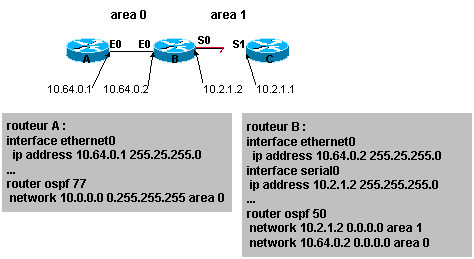
router(config)# router ospf process-id
2. Identifier
les réseaux IP qui participent ŕ OSPF. Quand on configure plusieurrs areas, il
convient de s’assurer d’associer les bons réseaux IP aux bonnes areas.
router(config-router)#network address wilcard-mask
area area-id
3. (optionnel) Si le routeur possčde au moins
une interface connectée ŕ un réseau non OSPF, celui-ci agit donc en tant que
ASBR.
La différence entre une area stub et totally
stubby :
stub area : Une stub area est une area configurée
pour refuser les advertisements (LSA) concernant les routes localisées en dehors
de l’AS.
Pour y parvenir, la stub area n’autorise pas le flooding de LSA de
type 4 et 5 vers la stub area. Un LSA de type de type 4 a pour
origine un ABRet contient les informations provenant des ASBR
de l’AS. Ce type d’information est normallement floodée au travers de la
backbone area sur l’ensemble des ABRs qui eux-męme aux routeurs internes.
Un
LSA de type 5 ŕ pour origine un ASBR, et contient les informations concernant
les informations de routes quant aux réseaux externes.
réduit la taille de la
link-state datatbase au sein de l’area, réduit les besoins en mémoire.
Les
LSAs de type 5 (external network) ne peuvent ętre floodés.
Le routage vers
une autre area ou vers un systčme externe est basé sur la route par défaut. Le
routeur envoie alors les données sur un ABR qui envoie un LSA 0.0.0.0. Cela
permet la réduction des tables de routage dans l’area puisque la route par
défaut remplace toutes les routes externes.
Une stub area est crée
typiquement dans le cas d’une topologie en étoile hub and spoke oů tous les
liens sont concentrés sur un point.
Totally stub area : spécifique ŕ Cisco réduit
encore le nombre de routes dans la table.
C’est une stub area qui bloque les
LSAs de type 5 (externes), et les summary (type 3 et 4) ŕ l’entrée de la
zone.
De ce fait seules les default route et les interarea sont les seules
routes que connaissent ce type de zones.
Les ABRs injectent les deafault
summary link 0.0.0.0 dans
Ce
type de zone représente donc la meilleure solution, ŕ moins qu’on utilise une
combinaison de routeurs Cisco et non Cisco.
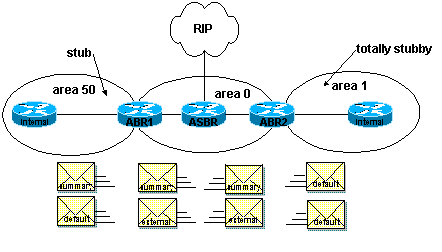
Ces zones disposent d’un seul point de sortie. Si il existe
plusieurs points d sortie par des routerus ABRs, le routage vers l’exterieur de
cette zone ne suivra pas forcément un chemin optimum puisque chaque routezur va
injecter une route par défaut.
Tous les routeurs OSPF ŕ l’intérieur d’une
zone stub ou stubby, que ce soient des internal ou dess ABRs routers, sont
configurés en tant que stub routeurs. De cette façon les routeurs deviennent
voisins (neighbors) et peuvent s’échanger des informations de routage.
Il
n’ya pas de configuration d’area lorsqu’on utilise un virtual link.
On ne
trouve pas d’ASBR dans une area stub ou totally stubby.
Ce type d’area n’est
jamais la backbone area.
La configuration d’une area stub ou totally
stubby
Une stub area est une area configurée pour refuser les LSAs
concernant les routes externes ŕ l’AS.
De ce fait les stub areas préviennent
la propagation de LSA de type 4 et 5..
UnLSA de type 4 est originaire d’un
ABR et contient des informations concernant ŕ propos des ASBRs.
Ces
informations sont normalement floodées ŕ travers la backbone area ŕ l’ensemble
des ABRs, qui eux-męme les floodent sur les internal routers.
Un LSA de type
5 et issu d’un ASBR et contient toutes les informations quant aux routes de
réseaux externes
Une stub area ne peut contenir de vitual link.
Comme une
stub area accepte des LSAs de type 3, les routeurs ŕ l’intérieur de l’area
peuvent acceder ŕ la fois aux intra et inter-area routes, mais doivent passer
par une default routes pour joindre les réseaux situés en dehors de l’AS
local.
Une totally stubby area est une area propriétaire ŕ Cisco, qui
n’accepte pas le floding de LSAs de type 3, 4, 5.
Les LSAs de type 3 sont
originaires d’ABRs et contiennent des link-state informations ŕ propos des des
areas connectées aux ABRs.
De ce fait une totally stubby area ne peut acceder
qu’aux intra-area routes et utilise une default route pour atteindre les réseaux
qui sont situés en dehors de sa propre area.
router(config-router)#area area_id
stub [no-summary]
area_id : décimal ou adresse
IP
no-summary : uniquement sur les ABRs connectés aux totally stubby
areas, prévient l’ABR d’envoyer des summaries dans une stub area. Cette option
est utilisée pour créer des totally stubby area.
router(config-router)#area area_id default-cost
cost
cost : cost des summaries routes, par défaut ce cost est
1.
Récapitulatif de configuration pour l’area 50 :
router(config-router)#area 50 stub —>
area stub
router(config-router)#area 50 stub no-summary
—> area totally
stubby
Un des bénéfices de l’utilisation d’une stub area connectée
directement ŕ la backbone area au travers de FR est que ce type de design évite
le flooding d’updates des external LSAs
Un autre type de design est de placer
l’ensemble des inetrfaces Frame-Relay dans l’area 0 ce qui permet la mise en
place de nombreuses stub areas ou de transit area. L’avantage est la création
d’area dans chaque location distante, mais posséde le désavantage du flooding de
LSAs ŕ travers tout le réseau.
La route summarization est la consolidation de nombreuses
routes dans l’annonce d’une seule.
La route summarization affecte directement
la BW utilisée, le CPU et la mémoire ŕ utiliser.
OSPF est un protocole de
type classless pour qui la summarization doit ętre configurée
manuellement.
Pour autoriser la summarization, il convient d’utliser la
commande area area-id range address-mask au niveau
de configuration router, oů addres-mask correspond au network ID et network mask
ŕ la route summarisée.
Les summarization ne sont pas liées aux interfaces, de
plus la summarization servant ŕ l’injection de routes au travers du backbone,
celle ci n’est réalisée que sur les routeurs de type border.
La commande
area-range est utilisée sur les ABRs pour summariser les
routes internes, ou interarea route nommées IA dans la table d routage. La
commande summary-address est utilisée sur un ASBR pour summariser une route
externe qui doit ętre injectée dans le domaine OSPF.
Si la summarization
n’est pas employée, chaque LSAs spécifique est envoyé au travers de la backbone
area.
Avec la summarization, seules les routes summarizées sont envoyées ŕ la
backbone area. Cet aspect est trčs important pour 2 raisons :
! Les LSA de type 3 et
4 peuvent ou pas contenir des routes summarizées.
Il existe 2 types de
summarization :
router(config-router)#area area_id
range address mask
address : summary
address
mask : subnet mask de la summariy
address
not-advertise : optionel, permet de supprimer la route oů
la paire préfix/mask correspondent.
tag : valeur utilisée pour contrôler
la redistribution par des routes maps.
exemple de
configuration :
router ospf 100
network 172.16.32.1
0.0.0.0 area 1
network 17.16.96.1. 0.0.0.0 area 0
area 0
range 172.16.96.0 255.255.224.0
area 1 range 172.16.32.0
255.255.224.0
La commande d’injection d’une default route sur un ASBR est
différente :
router(config-router)#
summary-address address mask [not-advertise] [tag
tag]
Une default route peut ętre propagée depuis un ASBR sur tous les routeurs de l’AS en utilisant la commande default-information originate. Ce type de commande est utilsé lorsque la connexion ŕ un prvider se fait par un point unique, au travers d’une route statique.
OSPF transporte les informations de subnet. Pour que
l’adsressage soit effectif, il convient qu’il soit hiérarchique.
La
configuration d’un virtual link :
router(config-router)#area area_id virtual-link router-id
router#
show ip ospf interface ethernet0
Ethernet0 is up, line protocol is
up
Internet Address 10.64.0.2/24 area0
Process ID 1, Router
ID 10.64.0.2, network Type Broadcast, Cost : 10
…
La commande show ip ospf sert ŕ déterminer le router
ID.
exemple de configuration :

R2 :
router ospf
63
network 10.3.0.0 0.0.0.255 area
1
network 10.7.0.0 0.0.0.255 area 3
area 1 virtual-link
10.3.10.5
R1 :
router ospf 100
network 10.2.3.0
0.0.0.255 area 0
network 10.3.2.0 0.0.0.255 area 1
area
1 virtual-link 10.7.20.123
show ip ospf border-routers č liste les ABRs et ASBRs
dans l’AS
show ip ospf
virtual-links č
montre l’état des virtual links
show ip ospf process-id
č donne des statistiques sur chaque area
connectée au routeur
show ip ospf database [network]
[summary] [asbr-summary] [external] [database-summary]č
donne le contenu des tables OSPF