1 Les principes du routage
Le routage est laction denvoyer (forwarding) une
information dun endroit à un autre.
Les routeurs envoient des informations
sur des destinations logiques.
Le routage assume 2 fonctions
majeures :
Le routeur est un périphérique de couche 3 qui utilise des
PDU (Protocol Data Unit) appelés paquets ou datagrammes. Le routeur sappuie sur
un adressage logique pour connaître source et destination.
Bien souvent les
protocoles de routage tels quIP sont "conectionless" sans connexion, le routeur
doit réaliser son meilleur effort (best effort) pour remettre ses
PDUs.
Pour fonctionner le routeur doit comprendre
ladressage logique quon lui demande.
Pour comprendre ladressage logique,
il convient que le protocole en question tourne sur le routeur.
Puis une fois
que ladressage logique est compris, il convient de connaître le chemin, la
route pour envoyer les paquets. Le routeur consulte sa table de routage et
conclue sur la validité de la demande dadressage quon lui formule.
Dans le
cas ou la destination est connue par le routeur, lopération suivante consiste à
envoyer le paquet sur la meilleure interface de sortie.
Les routeurs se
servent de métriques pour qualifier la qualité des chemins.
En cas de
métriques égaux, certains protocoles peuvent se servir de chemins
redondants.
! Pour utiliser une
default route la commande ip classless est obligatoire
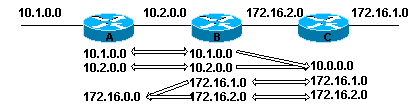
La
plupart des informations concernant le routage sont contenues dans la table de
routage.
I
172.16.8.0 [100/118654] via
172.16.7.9, 00:00:23,
serial0
I La méthode dont la route est apprise,
ici par IGRP
172.16.8.0 ladresse de réseau de
destination
100 ladministrative
distance
118654 le métrique
172.16.7.9 ladresse
logique du next hop
00:00:23 lage de lentrée en
heures :minutes :secondes
serial0 linterface de
sortie
Cest le critère de sélection entre plusieurs protocoles de
routage qui pointent sur la même destination.
Le choix se porte sur la valeur
la plus basse.
En tête nous trouvons la route statique toujours préférée à
une route dynamique, puis lordre se fait en fonction de la sophistication des
métriques :
|
Route
source |
Administrative
distance |
|
Connected
interface |
0 |
|
static route out an
interface |
0 |
|
static route to a next
hop |
1 |
|
EIGRP summary
route |
5 |
|
external
BGP |
20 |
|
internal
EIGRP |
90 |
|
IGRP |
100 |
|
OSPF |
110 |
|
IS-IS |
115 |
|
RIP V1, V2 |
120 |
|
EGP |
140 |
|
external
EIGRP |
170 |
|
internal
BGP |
200 |
|
unknown |
255 |
La définition du meilleur chemin est basée sur les
métriques.
Le coût dun path est la somme des métriques de tous les liens
pour aller à la destination.
Sil existe plusieurs chemins disposant du même
métrique vers une destination, alors le routeur va assurer du load balancing (ou
load sharing)
Par défaut les routeurs cisco supportent 4 chemins égaux mais
un maximum de 6 peut être atteint à laide de certains protocoles.
Dans le
cas de load-balancing certains protocoles utilisent des equal cost et dautres
des unequal cost (IGRP et EIGRP)
Le choix des interfaces pour le load
balancing se fait sur base de plusieurs critères :
Les routeurs essayent toujours détablir une relation avec
les routeurs voisins pour identifier les voisins et connaître la topologie du
réseau.
Le routage est basé sur un système de relayage :
La méthode de découverte des voisins dépend des protocoles de
routage, il peut sagir de broadcast ou de multicast.
Les protocoles de
routage établissent des relations de type "peer relationship" avec les routeurs
voisins en sappuyant sur les couches hautes (L4-L7).
Les protocoles de
routage séchangent des "hello packets" pour simuler des keepalives et maintenir
la communication avec les voisins.
Une fois que la topologie du réseau esr
découverte et que la table de routage contient le meilleur chemin pour toutes
les destinations, le routeur envoie le trafic. La fonction de forwarding du
trafic devient du switching.
De fait la résolution dadresse de L2 doit être
faite.
Le switching est la dernière fonctionalité du processus de
routage.
les différentes étapes du processus de routage :
1° Le
paquet est admis par le routeur parcequil contient la MAC-address du routeur en
destination. Puis ce paquet est bufferisé en mémoire à un emplacement
spécifique.
2° Le switching process cherche le réseau et/ou sous-réseau dans
la table de routage pour ladresse de destination.
Si le résultat est
probant, le switching associe ladresse de destination du réseau avec celle du
next hop et une interface de sortie.
3° Le switching process cherche à
connaître la MAC-address du next hop. Une requâte ARP est émise sur un LAN, ou
une recherche dans la table de map est faite pour un WAN. Le contenu de ces
tables est soit dynamique soit statique.
4° Len-tête de la trame est
réecrite. Ladresse de destination est la MAC-address du next hop, ladresse
source est la MAC-address du routeur et le CRC est évidemment recalculé. Au
niveau du L3 on décrémente le TTL et on ne touche (jamais) aux adresse logiques
(IP). Puis la trame est envoyée sur linterface de sortie.
Les protocoles de routage classful ne transportent pas
dinformations concernant la longeur du masque de subnet.
De fait ils ne
connaissent que les "major classes".
Il sagit de RIP V1 et IGRP.
La
summerization est automatique avec ces protocoles.
Il convient donc dêtre
vigilant sur la hierarchie du design avec des protocoles classful.
Le subnetting peut fonctionner avec des protocoles classful à condition que toutes les interfaces aient le même masque. Cette approche est gourmande en adresses réseau notammant lorsquil sagit dune liaison point à point entre 2 routeurs qui nécessitera un subnet complet.
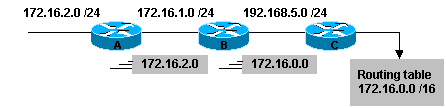
La summerization est automatique.
Si la mise à jour de la
route comporte un subnet identique à celui utilisé sur linterface de réception,
alors ce subnet sera maintenu.
Dans le cas contraire, le routeur appliquera
le subnet par défaut de la classe.
Les protocoles classless transportent des informations quant
à la longeur du masque. Il sagit de :
OSPF, EIGRP, RIP V2, IS-IS,
BGP.
Aves les protocoles classles la sumarization peut être controllée
manuellemnet au bit près.
Les protocoles classles utilisent des "triggered
updates" pour connaître les changements de topolgie.
La summarization permet
de contrôler la taile des tables de routage.
Les protocoles de routages
classless permettent dutiliser les subnets à bon escient en matière
dallocation grâce au support de VLSM (Variable Length Subnet Mask)
Les protocoles de type distance vector utilise le next hop
comme métrique. De plus les routing updates ne sont propagés que sur les voisins
directement connectés par un logical broadcast.
Les protocoles DV purs
envoient souvent la table de routage complète, on parle de "routing by rumor"
puisque la connaissance que possède un routeur de la topologie du réseau est
basée sur celle de son voisin.
Dans un paquet IP le champ Procol Number
définit le protocole de couche 4 contenu dans
La plupart des protocoles de routage disposent de leur propre gestion
des couches hautes et on trouvera donc des Protocol Numbers spécifiques.
La
plupart des protocoles Distance Vector utilisent lalgorithme Bellman-Ford pour
le calcul de route. EIGRP est un Advance Distance Vector Protocol et utilise
lalgorithme DUAL (Diffusing Update ALgorithme).
Le mécanisme de modification
de routage :
La route tombe, elle est retirée.
Le routeur envoit
immédiatement un triggered update au routeur voisin qui démarre son holdown
timer.
Ce dernier envoi en retour au routeur initial un reverse poisonning et
distribue de triggered updates aux autres routeurs directement
attachés.
Pendant le hodown timer la route est possibly down.
La route ne
sera mise à jour que dans le cas de réception dune route contenant un meilleur
métrique.
Les protocoles de type link-state sappuient sur des LSA
(Link-State Advertisement). Quand un lien est modifié, le routeur qui le détecte
envoie immédiatement un LSA qui est floodé sur le réseau (multicast). Puis
lorsqon est sur que tous les routeurs ont eus une copie du LSA, les routeurs
font tourner un algorithme et recalculent une nouvelle topologie.
De fait les
protocoles link-state nécessitent une hiérarchie dans le design du réseau, par
la création de zones logiques en ce qui concerne OSPF de façon à minimiser
limpact de la transmission des LSA.
La convergence est le temps nécessaire pour que tous les
routeurs dun réseau aient appliqués un changement.
Le temps de convergance
est affecté par
Le temps de converagnce dépend aussi de la rapidité à
détecter quun lien vient de tomber.
Il existe 2 méthodes :
Quand la détection est réalisée, ce sont les protocoles de
routage qui entrent en ligne de compte. En effet la plupart dentre eux
diusposent de mécanismes poiur éviter les boucles en faisnat intervenir des
timers (hold down timers)
Un protocole de routage ne pourra jamais converger
plus vite que le hold-down timer.

Le hold-down timer par défaut est de 180 sec.
1° Le
routeur C détecte quun de ses liens est tombé.
Il envoie un flash update
avec une poisoned route à B et D.
D crée un flash update et lenvoie à
E.
E crée un flash update et lenvoie à F.
C purge sa table de routage de
toutes les routes correspondant au lien qui vient de
tomber.
2° C envoie une demande pour une meilleure route à
tous ces voisins, 255.255.255.255 RIP V1 ou 224.0.0.9 RIP
V2.
3° D répond avec une poisoned route, B répond avec une
route dun meilleur métrique.
B est est immédiatement placé dans la table de
routage de C.
D continue à envoyer une poisoned route vers C dans ses
updates.
4° D est hold down timer en ce qui concerne la
route qui est tombée.
C envoie des updates contenant la nouvelle
route.
Ces updates ne sont pas pris en compte pad D tant que le hold down
timer tourne.
D continue denvoyer des poisoned route à
C
5° Dès que les routeurs D, E, F sortent de leurs hold down
timer, ils reçoivent la nouvelle route annoçée par C.
Leurs tables de routage
est mise à jour.
Du point de vue de F, la convergance est le
temps de détection + un hold down timer + 2 update time (DàE, EàF) + un update complet ou
partiel ce qui représente plus de 240 sec (un détail).
! Le timer suivant
après le hold down est le dead interval timer. Les updates concernant cette
route doivent parvenir afin lexpiration du dead interval, sinon la route est
retirée des tables.
! Lorsque le hold down
timer tourne, la route de C est possibly down.
Le hold-down timer par défaut est de 280 sec
1° Le routeur
C détecte quun de ses liens est tombé.
C envoie un flash update avec une
poisoned route aux routeurs B et D.
D crée un flash update et lenvoie à
E.
E crée un flash update est lenvoi sur F.
C purge lentrée
correspondant au lien tombé et enlève toutes les routes associées à ce
lien.
2° C envoie une demande pour une meilleure route à
tous ces voisins, 255.255.255.255 sur lensemble de ses interfaces y compris
celle qui est tombée.
D répond avec une poisoned route.
C envoie un flash
updsate sur toutes ses interfaces sans le lien tombé.
3°B
répond avec une route dun meilleur métrique.
Cette route est immédiatement
rajoutée dans la table de routage de C.
C nentre pas dans un hold down timer
parce que lentrée était déjà purgée.
C envoie un nouveau flash update
contenant la nouvelle route sur lensemble de ses
interfaces.
4° D est en hold down timer pour la route
tombée.
Quand C envoie un flash update avec la nouvelle route, D continue de
lignorer durant son hold down timer.
D continue denvoyer à C une route
poisoned à C dans ses updates.
5° Dès que les routeurs D, E,
F sortent de leurs hold down timers, ils reçoivent les flash update de C et
rajoute la nouvelle route dans leurs tables de routage.
Du
point de vue de F, la convergance est le temps de détection + un hold down timer
+ 2 update time (DàE,
EàF) + un update
complet ou partiel ce qui représente plus de 490 sec (un gros détail).
1° Le routeur C détecte quun de ses liens est tombé.
C
contrôle dans sa table de topologie si il nexiste pas un "feasible successor"
et ne trouve pas dalternative qualifiée.
C entre en
convergance.
2° C envoie une requête sur lensemble de ses
interfaces pour une nouvelle route concernant le lien tombé.
Les routeurs
voisins acquittent le requête.
3° D
indique quil ne possède pas de meilleure route.
4° B
indique quil possède une route avec une feasible distance plus
élevée.
5° C accepte le nouveau chemin avec le
métrique correspondant, le place dans sa table de topologie, et crée une
nouvelle entrée dans sa tale de routage.
6° C envoie un
update concernant cette nouvelle route sur lensemble de ses
interfaces.
Chaque voisin acquittent lupdate et le renvoient aux émetteurs.
Ces updates sont bidirectionnels et sont nécessaires pour sassurer que les
tables de routage sont bien synchonisées et que tous les
voisins
Du point de vue de F, le temps de convergence est le
temps de détection + query + réponse + update time.
La convergance seffectue
en 2 sec.
! La notion de hold
down timer disparaît. Par contre il existe encore un timer pour déterminer si
les voisins existent encore.
La convergance dOSPF
1° Le routeur C détecte quun de ses liens vient de
tomber.
Il entame une élection de DR sur le LAN, mais narrive pas à joindre
tous ses voisins (A).
C enlève la route de sa table et construit une "router
LSA" quil envoie sur lensemble de ses interfaces.
2° A la
recption de ce LSA les routeurs B et D copient lavertissemnt et le floode sur
lensemble de leurs interfaces.
(sauf sur celle dont il est issu).
3° Tous
les routeurs y compris le routeur C attendent 5 sec. après réceptiondu LSA et
font tourner lalgorithme Dijkstra apppelé SPF.
Après avoir fait tourner
lalgorithme, le routeur C rajoute une nouvelle route dans sa table de routage
en utilisant le lien série vers B tandis que les routeurs D, E, F mettent à jour
leurs métriques de leurs tables de routage à destination de ce
réseau.
Daprès le point de vue de F la convergance est le
résultat du temps de détection + LSA flooding +5 secondes.
Les 5 secondes ne
sont quune limite pour éviter de lancer plusieurs fois SPD dans le cas où un
lien est "flapping", quil tombe et reviennent rapidement.
La table de
routage :
La table de routage est visualisble par la
commande :
router# show ip route à visualistaion de
la table de routage
router# show ip route
n°_network
Lordre des routes de la table paraît aléatoire. En fait,
elle est optimisée en fonction des bits des adresses de routage pour le process
de recherche dadresses.
Les entrées de la table de routage sont limitées aux
meilleures routes pour toutes les destinations.
Si de multiples paths
existent, ils sont tous listés au travers de la table avec un maximum de
6.
Le process de routage IP va balancer le trafic sur lensemble des paths
égaux.
Le processus de routage maintient des routes sans boucles pour chaque
destination.
router# clear ip route * à permet de mettre à jour la
table de routage.
router# show ip
route
E2 172.22.0.0/16 [110/20] via 10.3.3.3
[110/20]
via 10.4.4.4, 01:02:03, Serial1/3 load balancing sur les 2 liens
[110/20]
via 10.5.5.5, 01:02:03, Serial1/3
1.8.4. Comparaison des protocoles de routage
|
Caractéristiques |
RIP
V1 |
RIP
V2 |
IGRP |
EIGRP |
OSPF |
|
Distance
Vector |
þ |
þ |
þ |
þ |
|
|
|
|
|
|
þ |
þ |
|
Automatic
route summarization |
þ |
þ |
þ |
þ |
|
|
support de VLSM |
|
þ |
|
þ |
þ |
|
Propriétaire |
|
|
þ |
þ |
|
|
Scalability |
small |
small |
Medium |
Large |
Large |
|
Temps de convergance |
Slow |
Slow |
Slow |
Fast |
Fast |
#show controllers serial X/Y è permet de connaître le type de connexion physique, DCE ou DTE ainsi que la clock source et identifie le type de câble
Ladressage IP a du faire face à 2 problèmes :
Les adresses privées :
110.0.0.0 à
10.255.255.255
172.16.0.0 à 172.16.31.255
192.168.0.0 à
192.168.255.255
les techniques quant à lopression raréfiante du nombre des adresses :
VLSM permet de rajouter des bits à ladresse de réseau et
crée le concept de subnet.
A laide dun plan dadressage bien conçu, VLSM
permet doptimiser ladressage hiérarchique.
On évite dutiliser le 1° et le
dernier subnet dun range.
Il peut y avoir confusion avec ladresse de réseau
sur le 1° subnet et confusion avec ladresse de broadcast avec le dernier
subnet.
Pour utiliser le subnet 0 :
001 -126 classe A
128 191
classe B
192 223 classe C
224
239 classe D
240 254 classe E
quelques adresses de classe D :
OSPF
224.0.0.5, 224.0.0.6
RIP V2
224.0.0.9
EIGRP 224.0.0.10
Les bénéfices de ladressage hiérarchique
Ladressage
hiérarchique fait quune seule adresse représente une collection
dadresses.
Ladressage hiérarchique permet de
Kesako ?
La route summarization est aussi appelée
route agregation ou supernetting.
La route summarization sert à réduire le
nombre de routes que maintient un routeur. Il sagit dune technique
dagrégation où un seul réseau représente une série de réseau.
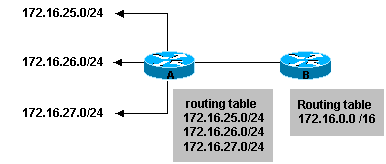
Un autre avantage dutiliser la route suumarization est de
pouvoir isoler les changements de topologie dun routeur à lautre.
Dans
notre figure si le lien 172.16.27.0 se met à déraillir (flapping, up and down
rapidly), la route summarizée ne changera pas. Ainsi aucun routeur externe
naura à modifier ses paramètres.
La summerization est adaptée à un
environnement composé de subnets où les adresses sont sur des blocks continus de
puissance de 2. Par exemple 4, 16, 51 adresses peuvent être représentées par une
seule entrée.
La summerization fonctionne avec la hierarchisation.
Les
protocoles classless réalisent la summarization ou lagrégation de routes sur la
base des adresse réseau paratgées au sein du réseau. De plus, ces protocoles
supportent lagrégation de routes sur base du subnet ainsi que VLSM.
Les
protocoles classful réalisent une summarization automatique au niveau de la
classe dadresse utilisée, mais ne supportent aucuns autres mécanismes de
summarization.
|
172.16.168.0/24 |
1010 1100 |
0001 0000 |
1010 1 |
000 |
0000 0000 |
|
172.16.169.0/24 |
1010 1100 |
0001 0000 |
1010 1 |
001 |
0000 0000 |
|
172.16.170.0/24 |
1010 1100 |
0001 0000 |
1010 1 |
010 |
0000 0000 |
|
172.16.171.0/24 |
1010 1100 |
0001 0000 |
1010 1 |
011 |
0000 0000 |
|
172.16.172.0/24 |
1010 1100 |
0001 0000 |
1010 1 |
100 |
0000 0000 |
|
172.16.173.0/24 |
1010 1100 |
0001 0000 |
1010 1 |
101 |
0000 0000 |
|
172.16.174.0/24 |
1010 1100 |
0001 0000 |
1010 1 |
110 |
0000 0000 |
|
172.16.175.0/24 |
1010 1100 |
0001 0000 |
1010 1 |
111 |
0000 0000 |
|
nb de bits |
8 |
8 |
5 |
|
|
Dans notre exemple le tronc commun est de 21 bits.
La
summarization se fera donc sur 172.16.168.0 /21

Un design basé sur VLSM permet dexploiter au mieux
lensemble du plan dadressage tout en préservant les tables de routage grâce à
la summarization utilisé conjointement avec un design hiérarchique.
Dans
notre exemple la summarization de fait à 2 niveaux :
Pour que la summarization fonctionne, il convient de respecter certains prérequis :
Lorde de recherche au travers dune table de routage
est
1° le subnet complet (the longest match)
2° le subnet qui correspond
au résumé.
172.16.5.33 /32 >
host
172.16.5.32 /27 >
subnet
172.16.5.0 /24 >
network
172.16.0.0 /16 >
block of network
0.0.0.0 /0 > default
La summarization doit être configurée manuellement pour
OSPF.
La summarization est automatique pour RIP IGRP EIGRP aux adresses
majeures (major network address boundaries)
La summarization ne peut
seffectuer dans le cas de réseaux discontinus.
Si plus dune entrée est
valide comme route de destination, le process de sélection de route privilégiera
lentrée la plus longue.
Quand les subnets sont discontinus, il faudra
désactiver la summarization sur EIGRP ou utiliser des protocoles classless.
CIDR nest pas une technique à proprement parler mais plus une recommendation aux ISP doptimiser leurs plans dadressage en agrégant des classes C
Dans le cas dune liaison poit à point, il nest pas
nécessaire deffectuer du gaspillage dadresses IP.
LorsquIp utilise une
interface unnumbered, cest ladresse de linterface à laquelle elle est liée
qui est employée.
IP unnumbered fonctionne
avec :
Ip unnumbered ne fonctionne pas
avec :
Ping fonctionne sur les interfaces
unnumbered de même que SNMP.
Une attention doit être portée quant à
lutilisation dinterfaces unnumbered qui sont connectés sur des adresses
majeures différentes. En effet certains protocoles de routage ne fonctionneront
pas.
router(config)# interface serial0
router(config-if)# ip unnumbered
ethernet0
Les routeurs ne transmettent pas les
broadcasts.
Delà peut se montrer gênant lorsquil sagit de requêtes
DHCP.

ip helper address envoie par défaut 8 ports UDP :
router(config)# ip helper-address
addresse_du_serveur
router(config)# ip forward-protocol udp [port]|nd|snds

router(config)# interface
Ethernet0
router(config-if)# ip address 172.16.1.100
255.255.255.0
router(config-if)# ip helper-address
172.16.2.2
!
router(config)# ip forward-protocol udp
3000
router(config)# no ip forward-protocol udp
tftp
Dans notre exemple nous remarquons que le helper est placé
sur linterface qui reçoit les broadcast et doit les traiter (transformation en
unicast)
Le second paramètre est dindiquer ladresse du serveur de
destination.
Puis en mode global on trouve la précision quant aux ports qui
seront traités : ici le port 3000 mais pas le port
69 (TFTP)
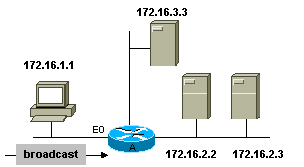
Le principe reste le même à lexception quil convient
dindiquer plusieurs adresses de serveurs, de plus on peut indiquer dans ce cas
une adresse de direct broadcast pour simplifier la configuration :
router(config)# interface Ethernet0
router(config-if)# ip address
172.16.1.100 255.255.255.0
router(config-if)# ip helper-address
172.16.2.255
router(config-if)# ip helper-address
172.16.3.3
!
router(config)# ip forward-protocol udp
3000
router(config)# no ip forward-protocol udp tftp