1. A
l’échelle d’un campus
Un switch permet de disposer d’autant de domaine de
collisions que de ports.
Malheureusement le switch n’englobe qu’un seul
domaine de broadcast.
1.1. Le
broadcast
Le broadcast est un gros consommateur de bande
passante.
De plus le broadcast est analysé au niveau de l’ensemble des
périphériques qui composent le réseau.
Les protocoles qui utilisent le
broadcast sont trčs nombreux :
- Arp request
- NetBIOS name request
- IPX get nearest server
- IPX
SAP advertisement des services d’un serveur
- RIP annoucements
- IGRP annoucements
Męme le trafic multicast est gros consommateur de
bande passante.
La solution quant au broadcast est de
- Segmenter
le trafic par l’utilisation de routeur.
- Segmenter
le trafic par l’utilisation des vlans.
Un vlan représente un domaine de
broadcast.
1.2. les
composants :
Les réseaux de type de campus utilisent
majoritairement 2 composants :
- Les
switches pour segmenter le trafic et réduire les broadcast par l’utilisation
de vlan
- Les
routeurs pour router entre les vlans
Pourquoi a t’on besoin de router entre les
vlans.
En fait si on veut que plusieurs vlans communiquent, on est obligé de
passer par une technique de couche supérieure.
Le bon design consiste alors ŕ
superposer des subnets aux vlans.
Par la suite il faudra un équipement
capable de comprendre ŕ la fois un vlan et un subnet.
Cisco distingue 3 types
de services
- Remote
service : un service proche de l’utilisateur mais sur un subnet
différent. L’accčs a ces services travers ou pas le backbone, par contre
traverse obligatoirement le domaine de broadcast.
- Enterprise
service : ce sont des services disponibles pour l ‘ensemble des
utilisateurs. Le trafic doit traverser le backbone et passe par la couche 3
(le subnet).
- Local service : reste local.
1.3. Layer 2 switching
:
Store and forward : copie complčte de la trame,
sűr mais peu performant.
Cut through : envoi de la trame dčs que la mac
dest est connue, cad trčs rapidement, rapide mais peu sűr.
Fragement free
analyse des 64 1° bytes, et on considčre que le reste est bon, rapide et sűr, le
meilleur rapport qualité prix.
Bénéfice du
routage :
- Contrôle
de broadast
- Contrôle
du multicast
- Optimisation
pour trouver me meilleur path
- Addressage
logique (L3)
1.4. Layer 3 switching :
Il s’agit de hardware based routing.
Cet
équipement sait
- Trouver
le meilleur chemin a la destination
- Vérifier
l’intégrité de la couche 3 par calcul du checksum
- Vérifier
l’expiration des paquets et les mettre ŕ jour
- Mettre
ŕ jour et transmettre les statistiques dans les
MIB
- Appliquer
les contrôles de sécurité
La différence entre un routeur et un switch layer 3
est que sur le routeur le switching est réalisé par le processeur, alors que sur
le switch layer3 celui-ci est réalisé par un ASIC
Les switchs haute
performances trait le switching de différentes façons :
Sur le Cisco
1200 GSR (Gigabit Switch Router) peut réaliser du switching en L3 grâce une
matrice crossbar
Sur les autres L3 switches, le switching est réalisé au
travers d’ASIC
1.5. Layer 4 switching (multi-layer
switching) :
Le layer 4 switching fait référence au layer 3
hardware based routing qui peut considérer les applications.
Le layer 4
switching est la possibilité de réaliser des décisions de
forwarding basées pas uniquement sur les mac address source et
destination, sur les IP address source et destination, mais aussi sur des
paramčtres de couche 4 (port TCP et UDP).
De plus, l’étude de la couche 4
permet d’identifier les applications, grâce ŕ quoi o peut réaliser de la
priorité sur le trafic et donc de réaliser de la qualité de service QoS
(vidéoconférence prioritaire sur e-mail).
1.6. Multilayer switch :
Le multilayer switching est basé sur
"route once, switch many".
Le multilayer chez Cico opčre en couche 3 et
4.
Le multilayer switching cherche ŕ identifier un flux. Dčs lors l’info est
passée en layer 2 et le reste du flux est switché.
Pour le multilayer
switching on a besoin de :
5000 ŕNFCC
(Netflow Feature Card)
6000 ŕ MSFC (Multilayer Switching
Feature card)
1.7. Le modčle hiérarchique
Cisco
Cisco propose une architecture basée sur le modčle
hiérarchique.
Il s’agit d’un modčle en trois
couches :
- access
layer : c’est le point d’entrée du réseau, composé de bandwidth partagée
et de services de layer 2 tesl que le filtrage et l’appartenence ŕ un
vlan.
- distribution
layer est la couche qui se charge de manipulation coűteuse du paquet telle que
l’agrégation d’adresses, un accčs workgroup ou départemental, la définition de
domaines de broadcast ou multicast, le routage inter-vlan, la translation de
médias, la sécurité. Il s’agit donc de la couche qui se charge de la "policy
based connectivity"
- core
layer doit transporter le plus rapidement possible les infos, et ne se charge
donc pas de manipulations de couche 3.
quels sont les équipements que nous trouvons dans
ces différentes couches :
access layer :
catalyst 1900/2900/3500
catalyst 4000 < 100
ports
catalyst 5000 > 100 ports
distribution layer
catalyst 5500
catalyst 6000
core
layer catalyst 5500
catalyst 8500 pour
backbone + PIM
catalyst 6500 pour backbone +
PIM
1.8. l’approche
par blocks
L’implémentation du modčle hiérarchique est basée sur une approche nommée building block.
- switch
block comprend ŕ la fois les switchs d’accčs et les switchs de distribution
(switch + routeur externe ou multilayer switch)
- core
block comprend les switchs qui forment le backbone (au travers du core
layer)
- server
block
- wan
block
- mainframe
block
Les caractéristiques du switch block
sont
- les
vlans et les subnets se terminent au distribution
switch
- les
access devices possčdent des liens redondants
- le
spanning-tree se ternine aux frontičres du switch
block
- tous
les switchs sont connectés ŕ un subnet commun de
management
Le core block représente le backbone.
Le core
block est nécessaire dčs lors qu’on possčde 2 switch-blocks ou
plus.
Idéalement le core-block n’utilise pas STP.
En effet STP est long ŕ
converger et bloque certains liens, ce qu’on ne désire pas dans le cas d’un
backbone.
On cherchera donc ŕ utiliser des protocoles de routage qui pourront
balancer le trafic sur des liens égaux.
A ce stade on le nombre de switchs
constituant le core-block est donc limité par le nombre de liens que le
protocole de routage retenu peut gérer.
Puisque les paquets sont passés au
travers de la couche de distribution, ils ont étés manipulkés en couche 3.
De
ce fait le lien au core-block se fera au travers de subnets spécifiques.
La
notion de vlan n’existe plus au niveau core, ce qui a pour conséquence de ne pas
avoir ŕ utiliser STP et donc de ne pas utiliser de
trunks.
1.9. Les
2 designs pour le core :
Le collapsed core quand les fonctions de
distribution et de core sont réalisées par les męme périphérique. Dans ce cas
STP bloque les liens redondants pour éviter les boucles. La redondance est
assurée ŕ la couche 3 par HSRP qui permet de définir une default-gateway
virtuelle.
Le dual core réalise utilise des équipements spécifiques ŕ ce
niveau pour réaliser la connexion entre la couche distribution et la couche
core. On cherchera une symétrie parfaite de liens entre les switchs-blocks et
les périphériques du core-block. Le layer 3 détermine quel est le lien ŕ
utiliser, tandis qu’HSRP permet le fail-over.
le nombre max
de blocks supportés en fonction du protocole de
routage :
|
routing
protocol |
max nb of supported
routing peers |
nb of subnet links to the
core |
max nb of supported
blocks |
|
OSPF |
50 |
2 |
25 |
|
EIGRP |
50 |
2 |
25 |
|
RIP |
50 |
2 |
15 |
Il existe donc 2 design
distincts
- layer2-layer3-layer2
- layer2-layer3-layer3
Le design le meilleur est certainement le L2-L3-L2.
Cependant le design L2-L3-L3 possčde quelques
avantages :
- une
convergence plus rapide
- le
load balancing automatique
- l’élimination
des peering problems puisque dans ce cas on instaure une hiérarchie entre les
routeurs de la couche distribution et ceux de la couche core (les pbs de
peering appartiennent au modčle L2-L3L-L2 ou les routeurs ne sont présents
qu’en couche distribution et répartis donc sur tous les
swichs-blocks ce qui pose des problčmes de transmission des
mises ŕ jour)
Utiliser du L3 au niveau core
revient ŕ mettre en place une technologie onéreuse.
2. La
connexion de l’access-block
2.1. Ethernet
Ethernet a été développé par un consortiom formé de
Digital, Intel, Xerox (DIX)
Puis l’IEEE a standardisé la technologie pour
donner 802.3.
802.3 et Ethernet sont
incompatibles.
|
L-2 ˝ haute |
IEEE 802.2
LLC |
|
L-2 ˝
basse |
IEEE 802.3
CSMA/CD |
|
L-1 |
IEEE 802.3 Physical
Layer |
Ethernet tourne ŕ 10 Mbps.sur des topologies
différentes :
la topologie est du type bus
- 10base2
ou cheapernet sur un segment de 185m
- 10base5
sur un segment de 500m
la topologie est du type
étoile
- 10baseT
pour des liens de 100 m sur du câble UTP
Dans ce cas le câble de patch ŕ l’élément actif est de
5m
La longeur du câble entre panneaux est de 90m
La rčgle des 5/4/3 doit ętre
respectée :
- 5
segments maximum
- 4
éléments actifs maximum
- 3
segments peuplés
Ethernet utilise CSMA/CD comme méthode
d’accčs.
2.1.1. La
trame Ethernet
La trame Ethernet est de longueur variable.
La
taille inférieure est de 64 octets.
La taille maximum est de 1518
octets.
Composition d’une trame
Ethernet :
|
8 octets |
2 ou 6 octets |
2 ou 6 octets |
2 octets |
46 ŕ 1500 octets |
4 octets |
Préambule
Adresse de DEST. Adresse SRC.
Type de trame Données
CRC
Le préambule est composé d’une suite de 0 et de 1
Il
permet au récepteur de se synchroniser.
Le champ CRC sur 32 bits permet au
coupleur de détecter les erreurs de transmissions.
Le champ type de trame
permet ŕ la station de connaître immédiatement le type de données transportées
dans la trame.
Le format de l’adresse Ethernet est de 48 bits : 24
octets définissent le constructeur, les 2’ autres octets donnent un n° de
carte unique.
runt : trame inférieure ŕ 64 bytes.
jam : Il
s’agit d’une trame de bourrage qui est émise par une station, le plus souvent
celle qui vient d’émettre et qui vient de se rendre compte d’une collision, afin
de prévenir les autres stations de démarrer un compteur
d’attente.
2.2. Fast-ethernet
Fast ethernet peut ętre utilisé ŕ tous les étages du
modčle hiérarchique Cisco.
|
Technologie |
catégorie de câblage |
longueur du câble |
|
100baseTX |
EIA/TIA categorie 5 (UTP) 2
paires |
100 m |
|
100baseT4 |
EIA/TIA categorie 3,4,5 (UTP) 4 paires
1/2 duplex only |
100 m |
|
100baseFX |
MMF 62,5/125 fibre
multimode |
400 m |
Les performances de Fast-ethernet peuvent ętre
améliorées en utilisant du full-duplex.
Les transmissions en full-duplex
utilisent 1 paire distincte pour la transmission et la réception. De ce fait la
détection de collision ainsi que les fonctions de loopback ne sont plus gérées.
La communication est considérée comme du point ŕ point.
Les caractéristiques
standard d’Ethernet ne sont pas modifiées sous Fast-ethernet, l’accčs au média
se fait toujours en utilisant la méthode CSMA/CD. De plus la taille de la trame
reste inchangée.
On essaiera d’implanter Fast-ethernet dans la connexion
entre les switchs et si possible en full-duplex.
2.3. Gigabit
Ethernet
Le but de gigabit-ethernet était de ne pas toucher ŕ la
couche LLC ˝ haute.
Pour y parvenir de nombreux changements ont été opérés en
couche 1.
2 technologies ont été regroupées : IEEE 802.3 Ethernet et
ANSI X3TII Fiber-channel pour donner 802.3z.
|
L-2 ˝ haute |
IEEE
802.2.LLC |
|
L-2 ˝ basse |
CSMA/CD ou Full-duplex Media Access
Control (MAC) |
|
L-1 |
8B/10B
encodage/décodage |
|
L-1 |
Serializer/Deserializer |
|
L-1 |
Connetceur |
|
Technologie |
Catégorie de câblage |
longueur du câble |
|
1000baseCX |
Cuivre STP |
25 m |
|
1000baseT |
Cuivre EIA/TIA catégorie 5 (UTP) 4
paires |
100 m |
|
1000baseSX |
Fibre multimode 62,5/50 µm
780nm |
260 m |
|
1000baseLX |
Fibre monomode 9 µm
1300nm |
3 km (Cisco supporte jusqu’ŕ 13
km) |
On cherchera ŕ connecter les liens entre la couche distribution et la couche core en gigabit-ethernet ainsi que les liens qui joignent les différents équipements de la couche core.
2.4. Le
port console d’un switch catalyst
Il existe 2 types différents de connexion ŕ un port
console d’un switch Cisco :
la prise RJ 45 utilise un câble rollover
(totalement croisé)
la prise DB25 utilise un câble straight
(droit)
3. La
configuration d’un switch
3.1. Le
password
Le mode privilčge 1 permet ŕ l’utilisateur de se connecter en
EXEC-mode.
Le mode privilčge 15 permet ŕ l’utilisateur de se connecter en
ENABLE-mode
ios
based :
Switch(config)#enable password level 1
password
Switch(config)#enable password level 15 password
set
based :
Switch(enable) set password
enter old
password :
enter new password :
retype new
password :
password changed
Switch(enable) set
enablepass
enter old password :
enter new
password :
retype new password :
password changed
3.2. Le nom de la machine
ios
based :
Switch(config)#hostname le_nom_du_switch
set
based :
System(enable) set prompt
le_nom_du_prompt
System(enable) set system name
le_nom_du_switch
L’adress IP
L’adresse IP d’un switch sert au
management, identifier le périphérique, accéder par telnet …
ios based :
Switch(config)#ip address addr
subnet
Switch#sh ip
IP address, subnet mask, default gateway,
management vlan=1, domain name, name server 1 :, name server 2 :, HTTP
server : enabled, HTTP port : 80, RIP enabled ?
set
based :
Il convient d’affecter une adresse IP ŕ l’interface logique
in-band :
Switch(enable) set interface sc0 ip
address netmask broadcast address
Puis il convient d’associer cette
adresse ŕ un vlan
Switch(enable) set interface sc0
vlan
Si on ne précise pas de vlan, automatiquement l’adresse ip de
management sera associé au vlan 1
Switch(enable) show
interface
s10 :flags=51<UP,POINTOPOINT,RUNNING>
slip 0.0.0.0 dest
0.0.0.0
sc0 :flags=63<UP,BROADCAST,RUNNING>
vlan1 inet 172.16.1.144 netmask 255.255.0.0 broadcast
172.16.255.255
rq :sc0 pour System Console 0
3.3. L’identification des ports
ios based :
Switch(config-if)#description
description_du_port
Switch(config-if)#description "description du
port" ŕ quand on
utilise des blancs dans le texte
set
based :
Switch(enable) set port name mod/port
description
pou clearer une description de port
Switch(enable)
set port name mod/port ŕ suivi de CR
3.4. Définir la vitesse et le mode d’un port
ios
based :
Switch(config-if)#speed 10|100|auto
set based :
Switch(enable) set port
speed mod/port 10|100|auto
le mode duplex
ios
based
Switch(config-if)#duplex auto|half|full|full-flow-control|half
Switch#show
interface ethernet 0/4
Ethernet 0/4 is enabled
Hardware is built-in
10base-T
Address is 0090.8678.9743
MTU 1500 bytes, BW 10000
Kbits
802.1d STP state : Forwarding Forward
transitions : 2
Port monitoring : Disabled
Unknown Unicast
Flooding : Enabled
Unregistered Unicast Floodng :
Enabled
Description : PC_TO_ACCESS_SWITCH
Duplex Setting : Full
duplex
Back pressure : Disabled
set based :
Switch(enable)
set port duplex mod/port auto|half|full|full-flow-control|half
Switch(enable)
show port mod/port
Port Name
Status Vlan
Level Duplex
Speed Type
--------
------- ------
--------- --------
------
2/4 connected
1 normal
full 100
10/100BaseTx
RQ :
Sur les switchs de la série
29xx,4000,5000, les ports ne sont pas automatiquement enabled
set port
enabled en mode privilege
3.5. La vérification de la connectivité :
La vérification de la connectivité se fait par la commande
ping
La réponse ŕ une commande ping dépend du type d’IOS ( !!!!! ou ip
address is alive)
On pourra utiliser la commande traceroute sur certains
switchs
4. Les VLANS
Les vlans représentent des domaines de
broadcast.
L’appartenance ŕ un vlan se fait sur base d’un port de
switch.
Un vlan est réparti géographiquement dans un périmčtre proche. De
plus dans un design de type campus on cherchera ŕ ne pas faire tourner STP entre
les core-switchs. De ce fait le design impose de ne pas établir de vlans de part
et d’autre des core-switchs.
Un vlan end to end est défini sur un ou
plusieurs switchs.
Les vlans permettent
- une meilleure utilisation de la bande-passante
- une forme de sécurité
- le load balancing au travers de multiples paths.
- l’isolation des problčmes réseau
Revenons sur le point du load-alancing. Pour effectuer un
lien entre des vlans différents on est obligé de passer en layer 3.De ce fait on
cherchera ŕ superposer des subnets aux vlans. Ainsi les vlans pourront utiliser
(indirectement) des techniques de routage et donc de bénéficier de load
balancing.
Il existe 2 types de vlans :
- les vlans end to end
- les vlans locaux
L’appartenance ŕ un vlan peut ętre
statique par définition
des ports des switchs
dynamique par VMPS Vlan Member Policy Server sur lequel
on configure la relation entre un port et une Mac address
les commandes
switch(enable) set vlan vlan_number
module/port
switch(enable) clear vlan
vlan_number
switch(enable) show vlan
NLes vlans dynamiques ne sont
pas gérés sur FEC
4.1. Le trunk
Le trunk sert ŕ transporter des informations de 1 ou
plusieurs vlans, d’un device ŕ un autre (switch ŕ switch ou switch ŕ
routeur).
Le trunk fonctionnre en fast ou gigabit ethernet.
Un trunk peut
transporter tous les vlans ou ętre limité au transport de quelques vlans.
Un
trunk dispose d’un vlan natif qui est utilisé en cas de perte du trunk.
La
commande show port capabilities peut renseigner ce que le port peut transporter
comme trunk.
L’identification d’un trunk se fait par une couleur apportée par
le tagging. Cette couleur disparaît ŕ la destination qui ne voit qu’une trame
normale, mais elle est conservée par l’ensemble des sitches traversés pour
connaître lidentité du vlan.
Le trunk transporte
- les infos du vlan
- les datas
- les broadcasts
Le vlan doit ętre identifié au travers du trunk, il faut donc
qu l’on dispose d’un niveau de renseignements. Ce niveau est apporté soit par
une encapsulation soit par un tagging.
Le trunk donne une couleur ŕ la
trame.
Dčs que la trame est sortie du trunk, le switch enlčve la couleur de
telle façon que la station finale ne voit qu’une trame normale.
4.2. les encapsulations de trunk :
ISL Inter Switch Link cisco elle rajoute 26 bytes ŕ la trame
ethernet (dont 10 bit pour le vlan-ID)č modification du header et
du CRC, on parle d’encapsulation
802.1q dot1Q insčre les infos de vlan, on
parle de tagging
802.10 cisco insertion des informations de vlan au travers
d’une trame FDDI
LANE LAN Emulation standard IEEE de transport des infos de
vlan sur ATM
|
Méthode d’identification |
Encapsulation |
Tagging |
media |
|
802.1Q |
NO |
YES |
Etherenet |
|
ISL |
YES |
NO |
Ethernet |
|
802.10 |
NO |
NO |
FDDI |
|
LANE |
NO |
NO |
ATM |
Les encapsulations supportées par les switches diffčrent d’un
matériel ŕ l’autre (ex le 4000 ne supporte que 802.1q).
switch(enable) show port
capabilities
4.2.1. L’encapsulation ISL :
L’encapsulation ISL nécessite 30 bytes pour :
26
bytes header et 4 bytes tail
vlan id sur 15 bits dont 10 servent au
n° de vlan soit 2exp10=1024 vlans
DA Distribution Address pour le
multicast
L’encapsulation ISL fonctionne sur Ethernet, token-ring, FDDI,
ATM
L’encapsuation ISL fonctionne de maničre plus rapide que 802.1q puisque
cette encapsulation est réalisée en hardware, alors que 802.1q est réalisée par
software.
L’encapsulation Isl rajoute 30 bytes et ne peut ętre compprise que
par des "devices Isl aware".
4.2.2. L’encapsulation 802.1q :
Il s’agit d’une méthode standardisée qui permet le transport d’informations de vlans sur des matériels différents.
|
Initial Mac
Address |
2-bytes
TPDI
2-bytes
TCI |
initial
type/data |
new CRC |
2 bytes tag protocol identifier (TPID) : Ce champ
possčde une valeur fixe de 0x0180 ce qui signifie qu’il s’agit d’une trame qui
transporte des informations 802.1q ou 802.1p
2 bytes Tag
Control Information (TCI)
3 bit user priority
1 bit canonical format (CFI
Indicator)
12 bits vlan identifier (VID)
La trame possédant des
infos 802.1q rajoute 4 octets ŕ la trame normale, ce qui
nous ramčne dans un cas extręme ŕ 1518+4=1522 octets.
Une
trame de 1522 octets est appelée baby giant. Cette trame est admise sur un lien
ethernet, mais elle n’est comprise que par les équipements spécifiques (switches
ou routeurs)
4.3. La négociation d’un trunk
Le protocole DTP (Dynamic Trunk Protocol) gčre la négociation
de trunks d’un switch ŕ l’autre.
Le paramčtre nonnegotiated dans
l’établissement d’un trunk supprime le protocole DTP sur l’interface en
question.
Depuis la release 4.2 l’autonegotiacion fonctionne sur ISL et sur
dot1q. Ce n’est pas le cas sur les release précédentes ou seule ISL supporte
l’autonégociation.
Durant la négociation d’un trunk, le lien ne participe
plus ŕ STP.
Quels sont les possibilités d’autonégociation :
on
ŕ
on, auto, desirable
auto ŕ on, desirable
(le lien peut devenir un trunk, mais on ne le souhaite pas)
desirable
ŕ
on, auto, desirable (le lien souhaite devenir un
trunk)
nonnegotiated ŕ on (on ne tient pas compte
de DTP)
off ŕ
off
switch(enable) set trunk mod/port [on | off | desirable | auto |
nonnegotiate] vlan_range [isl | dot1q dot10 | lane | negotiate]
Port(s)
mod/port trunk mode is set to on.
…
On peut sélectionner
manuellement des vlans qui ne circuleront pas sur le trunk :
switch(enable) clear trunk mod/port
vlan#-#
Quand un vlan est supprimé,
les ports passent en mode disable.
switch(enable) show
trunk mod/port
switch port mode
Encapsulation Status
Native vlan
---------
------------------ ----------
--------------
1/1 desirable
isl trunking
1
port vlans allowed on trunk
---------
------------------ ----------
--------------
1/1 port
1-100,250,500-1005
port vlans allowed and active in
management domain
---------
------------------ ----------
--------------
1/1 1,521-524
port
vlans in spanning tree forwarding state and not pruned
--------- ------------------ ---------- --------------
4.4. VTP
VTP maintient les configurations de vlans consistantes au
travers du réseau switché.
VTP est un protocole de type message qui utilise
les trames de type trunk de couche 2 afin de gérer le fait d’ajouter, enlever et
effacer des vlans.
VTP permet de :
- maintenir les configurations de vlan consistantes au travers du réseau
- de réaliser un lien entre un backbone ethernet et un backbone rapide tel que ATM LANE ou FDDI
- un monitoring précis des vlans
- une configuration plug & play.
- des reports dynamiques lors de l’ajout d’un vlan
- optimiser le path quand un vlan est répartit sur plusieurs switches.
Le domaine de management VTP doit ętre créé avant que ne le soient les vlans.
Tous les switchs au sein du męme domaine VTP partagent les infos concernant l’ensemble des vlans.
- le domaine de management
- un numéro de révision de configuration
- la connaissance des vlans et de leurs paramčtres spécifiques.
4.4.1. Les différents mode de VTP :
server (défaut) création, modification,
effacement
client ne peut créer, changer, effacer, ne
préserve pas les vlans au reboot
transparent ne participe
pas ŕ un domaine VTP, il n’avertit pas de sa configuration ni ne se synchronise
sur d’autres configurations.
Les messages VTP sont envoyés
au travers des trunks sur une adresse multicast.
A chaque modification de la
topologie le "revision number" est incrémenté.
Il existe 2 types
d’advertisements :
- Les requętes émises des clients lorsqu’ils démarrent
- Les réponses des serveurs.
- Advertisement request from client
- Summary advertisement : toutes les 300 sec sur le vlan1 et ŕ chaque changement de topolgie.
- Subset advertisement : contient les détails d’un vlan
- management domain name
- configuration revission number
- MD5 digest est la clé quand un mot de passe est échangé
- updater identity
- vlan ID (ISL ou 803.1q)
- vlan names
- 802.10 SAID values (FDDI)
- VTP domain name
- VTP configuration revision number
- vlan configuration incluant la MTU pour chaque vlan
- format de la trame
déterminer la version de VTP qui va tourner dans
l’environnement.
Un switch sera membre d’un domaine existant ou d’un nouveau
domaine. Dans ce cas il convient de créer le nom du nouveau domaine ainsi que le
mot de passe.
Puis choisir le mode VTP pour le switch
4.4.2. Les nouveautés de VTP V2
VTP V2 supporte :
- token-ring switching et vlan
- Unrecognize Type Length Value (TLV). Un serveur ou un client VTP propage les changements sur ces autres trunks. les Unrecognized TLV sont sauvegardés en nvram.
- Version dépendant Transparent mode. Un switch transparent en VTP V1 examinait les messages du domain ainsi que leur version et ne forwardait le message que si domaine et version concordaient. En V2 en mode transparent, les messages sont envoyés sans contrôle de la version.
- Contrôle d’intégrité. En V2 l’intégrité des vlans est testée (nom des vlans et valeurs) que lorsqu’elles sont rentrées en ligne de commande ou par SNMP. L’intégrité n’est pas testée lorsqu’elle provient d’un message VTP ou de la nvram. Si le digest d’un message VTP est correct son information est acceptée sans autres contrôles. Si un switch est capable de fonctionner en V2, il pourra s’intégrer dans un domaine V1 ŕ condition que la V2 soit disable sur le switch.
si le réseau tourne sous token-ring il faut utiliser VTP
V2.
Si tous les switchs sont capables de tourner en VTP V2, il suffit de
passer la commande set vtp enable v2 sur un seul switch. La version va se
propager sur tout le domaine.
switch(enable) set vtp
v2 enable ŕ sur un seul switch, si tous les switches du
réseau peuvent tourner sous VTP V2
switch(enable) set vtp domain
domain_name mode server | client | transparent
passwd password
et le tout en une commande :
switch(enable) set vtp domain bcmsn_block2
mode server
switch(enable) show vtp
domain
Domain name Domain Index VTP
Version Local Mode Password
-----------------
-------------- ---------------
------------
bcmsn_block2 1
2 server
-
Vlan count
max Max-vlan-storage Config
Revision Notifications Last
updater
---------------------
------------------- ----------------
---------------
33 1023
0 disabled 172.20.52.124
V2
Mode Pruning PruneEligible on
vlans
-----------
----------------------------
disabled
disabled 2-1000
vtp statistics :
summary advts
received
subset advts received
request advts received
summary advts
transmitted
subset advts transmitted
request advts
transmitted
switch(enable) clear vtp statistics
4.4.3. VTP pruning
Pruning=élégage
Le VTP pruning permet l’optimisation de la
bande-passante en réduisant la quantité non nécessaire de
trafic floodé comme les broadcasts les multicasts ainsi que les paquets unicasts
floodés.
Le pruning consiste ŕ envoyer le trafic intéressant uniquement sur
les trunks les plus directs. Imaginons un réseau composé de 8 switchs en
arborescence. Il existe un vlan réparti entre le switch le plus bas au switch le
plus haut. Le pruning va faire de telle sorte que le trafic sera concentré sur
les liens les plus directs et ne passera pas par les autres liens.
Le vlan1
n’est pas prune eligible.
Les vlans 2 –1000 sont prune eligible.
switch(enable) set vtp pruneeligible
vlan_range
switch(enable) clear vtp pruneeligible
vlan_range
switch(enable) show trunk mod/port ŕ pour afficher
les infos de VTP pruning
5. STP ou la gestion des liens redondants
Bridging transparant : dans ce mode le bridge ne touche
pas ŕ la trame. Le bridge se contente de lire l’adresse source et l’adresse
destination et puis c’est tout.
Un broadcast est envoyé sur tous les ports
exceptés celui sur lequel il ŕ été reçu.
Si l’adresse de destination n’est
pas connue, un unknown unicast, le bridge renvoie la trame sur tous les ports
exceptés celui sur lequel il a été reçu.
Transparant bridging fonctionne trčs
bien tant qu’il n’existe pas de liens redondants.
Les liens redondants
amčnent :
L’instabilité de la CAM table (table des adresses Mac)
la
possibilité de rencontrer des trames dupliquées
introduit des boucles
5.1. STP : la solution
Spanning Tree (STP) exécute un algorithme appelé
Spanning-Tree Algorithm (STA) (ouah ces américains, quelle
imagination !!!)
Pour trouver des liens redondants, STA choisi un point
de référence dans le réseau et calcule les liens redondants ŕ partir de ce point
en désignant des liens comme forwarding et d’autres comme blocking.
STA
établi une topologie sous forme d’arbre inversé.
L’ensemble
des switchs qui font tourner STP utilisent des BPDU (Bridge Protocol Data
Unit)
Les BPDU sont envoyés toutes les 2 sec. sur chacun des
ports.
L’échange de ces messages (BPDU) permet de :
- élire un switch en tant que Root
- élire un designated switch pour chaque segment
- éliminer les boucles dans le réseau switché en plaçant les ports dans un état bloqué.
5.2. La composition d’un BPDU
|
Field | |
|
2 |
Protocol
ID |
|
1 |
Version |
|
1 |
Message
Type |
|
1 |
Flags |
|
8 |
Root ID |
|
4 |
Cost of
Path |
|
8 |
Brige ID |
|
2 |
Port ID |
|
2 |
Message
Age |
|
2 |
Maximum
Time |
|
2 |
Hello Time |
|
2 |
Forward
Delay |
5.3. Les étapes de STP
Pour STP : less is
best
5.3.1. Election du Root bridge
La sélection du Root bridge s’opčre ŕ partir des critčres
suivants :
La plus basse des priorités
La plus basse des adresses
Mac
La priorité est codée sur 2 bytes. La valeur par défaut est 0000 8000
soit 32768
La Mac-address est codée sur 6 bytes.
Sur le Root bridge, tous
les ports sont Designated.
Tous les ports Designated sont dans l’état
Forwarding.
Le cost des ports du Root = 0
5.3.2. Détermination du Root port
Le Root port est aussi appelé Forwarding Port.
Chaque (non
Root) bridge établit un Root port.
Le root port est déterminé sur base du
coűt le plus bas jusqu’au Root bridge.
En cas d’égalité, l’élection se fait
sur base de la Bridge-ID (la plus basse).
En cas d’égalité, l’élection se
fait sur base du Port-ID (le plus bas).
Ces ports passent automatiquement
dans l’état forwarding.
5.3.3. Détermination des designated bridge
5.4. Les différents états STP
- Blocking Tous les ports démarrent dans cet état afin d’éviter de créer des boucles dčs le démarrage. En mode blockig, un port continue ŕ recevoir et comprendre des BPDU.
- Listening 15 sec Le switch détermine durant ce laps de temps si il exite d’autres chemins vers le Root bridge. Durant cette période le port écoute les trames mais ne peut en recevoir ni en transmettre. De plus aucune information n’ira enrichir la table du switch. Le Listen mode sert ŕ établir que le port en train de devenir pręt ŕ transmettre mais qu’il veut attendre encore un peu pour ętre sur de ne pas créer de boucles (forward delay).
- Learning 15 sec identique au mode Listen ŕ la différence que le port peut enrichir sa Cam table des adresses apprises.
- Forwarding
- Disable (off)
5.5. BPDU timers
- Hello time :2 sec.
- Maximum Age : 20 sec
- Forward Delay : 15 sec.
5.6. Changement dans la topologie
Quand un changement se produit dans la topolgie, les ports
non-designated qui se trouvaient dans l’état blocking, passent en état
forwarding.
Quand un port ne reçoit plus de BPDU durant la période MAXAGE, un
nouveau Spanning Tree est recalculé.
Un bridge se rend compte que un de ses
liens est down. Le bridge envoie un BPDU de type topology change (1 byte dans le
champ flag) ŕ destination du Root bridge. Le bridge renverra ce BPDU jusqu’ŕ ce
qu’il reçoive un acquittement en retour du designated bridge.
Le designated
bridge renvoie un acquittement au bridge ayant annoncé le changement.
Quand
le Root bridge reçoit le BPDU, il modifie ses propres BPDU pour indiquer un
changement de topologie.
Le Root bridge fixe le changement de topologie pour
une période égale ŕ la somme du forward delay et du MAx Age, soit 35 sec. pour
les valeurs par défaut.
Un bridge qui reçoit le message de changement de
configuration de topologie utilise son forward delay pour vieillir ses entrées.
Ce dernier processus évite d’attendre les 5 min. fatidiques
STP est recalculé
ŕ chaque changement de topologie.
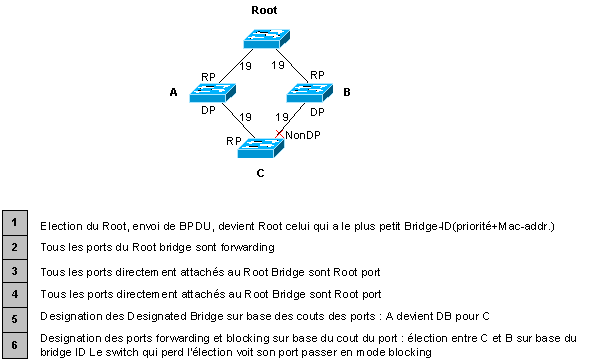
1° étape : élection du Root Bridge
Au départ tous les switchs se considčrent comme Root.
Le switch disposant soit de la priorité soit de la Mac address la plus basse devient Root
2° étape : choix des Root ports
Définition des ports cost
|
Anciens coűts |
Nouveaux coűts |
|
10M ŕ 100 |
10M ŕ 100 |
|
100M ŕ 10 |
100M ŕ 19 |
|
|
155M ŕ 14 |
|
|
1G ŕ 4 |
|
|
10G ŕ 2 |
|
catalyst 1900 |
catalyst 5000 |
Le Root considčre que tous ses ports ont un cost de 0
Les
routeurs directement au Root attachés ajoutent le cost A0=0, A1=0+19
- A coűts égaux, intervient le port ID : priorité (32 par défaut)+valeur : 8001 pour le port 1, 8002 pour le port 2 …
3° étape : designation des Designated Bridge :
A
devient designated bridge pou C sur base du calcul du coűt.
Puis élection
entre C et B par le biais de la bridge ID la plus basse.
L’autre switch voit
son port bloqué
Les switchs font tous du STP par défaut.
les commandes :
switch(enable) set spantree
enable
switch(enable) set spantree enable mod/port
switch(enable)
set spantree disable mod/port
switch(enable) set spantree enable
all
Spantree enabled
Il est trčs important que STP tournen sur tous
les ports et surtout sur les trunks oů le risque de rencontrer des boucles est
le plus grand.
ios
based :
switch(config)#spantree
vlan-list
switch(config)#no spantree vlan-list
5.7. La vérification de STP :
switch(enable) show spantree
VLAN
1
Spanning tree enabled
Spanning tree type
ieee
Designated Root
00-50-bd-18-a8-00
Designated Root
Priority 8192
Designated Root cost
0 ŕ indique qu’il s’agit bel et bien du
Root
Designated Root port 1/0
ŕ Le
port en direction du Root
Root max age
time 20 sec Hello time 2
sec Forward delay 15 sec
Bridge
ID MAC ADDR 00-50-bd-18-a8-00 ŕ valeur identique
au Root, indique qu’il s’agit du Root
Bridge ID priority
8192 ŕ valeur identique au Root, indique qu’il s’agit
du Root
Root max age time 20
sec Hello time 2 sec
Forward delay 15
sec
Port Vlan
Port-State Cost
Priority Fast-Start
Group-Method
-----
------------ -----
-------- -----------
------------------
2/1 1
forwarding 19
32 disbled
2/2
1 forwarding
19 32
disbled
Designated Root cost
ŕ Le coűt total jusqu’au Root bridge par le chemin le plus
court.
Root timers ŕ Les
valeurs des timers du
switch#show spantree
VLAN1 is executing the IEEE
compatible Spanning Tree Protocol
Bridge Identifier has priority 32768,
address 0090.866F.D000
Configured hello time 2, max age 20, forward delay
15
Current Root has the priority 32768, address 0050.BD18.A800
Root port
is FAstEthernet 0/26, cost of the root path is 10
Topology change flag not
set, detected flag not set
Topology changes 60, last topology change occurred
0d14h15m09s ago
…
Port Ethernet 0/25 of VLAN1 is
Forwarding
Port PAth Cost 100, Port Priority
128
Designated Root has priority 32768, address
0050.BD18.A800
Designated Bridge has priority 32768,
address 0090.866F.D000
Designated Port is Ethernet 0/25,
path cost is 10
Timers : message age 20, forward
delay 15, hold 1
5.8. PVST
PVST : Per Vlan Spanning
Tree
STP par vlan représente une solution élégante qui va calculer la
meilleure topolgie au sein d’un vlan.
Les catalyst 1900 et 2820 supportent un
maximum de 1005 vlans et PVST peut ętre activé sur 64 vlans.
L’inconvénient
est que le trafic de BPDU augmente.
Le trunk qui supporte PVST tourne sous
l’encapsulation ISL.
IEEE 802.1q utilise une approche nommée mono STP, ou
common STP (CSTP), 1 seule instance de STP pour tous les vlans.
ce qui a pour
avantage de faire circuler moins de BPDU, mais qui n’utilise pas forcément la
meilleure topologie.
802.1d est en cours de redéveloppement pour faire
tourner une instance de STP/vlan.
PVST+ :
PVST+ est l’extension de
PVST qui permet une intégration de 802.1q (réception/transmission sur le bridge
group Mac-address 01-80-c2-00-00-00).
produit une interopérabilité avec
802.1q
transporte les BPDU PVST par un tunnel au travers d’un vlan 802.1q en
tant que multicast.
teste les inconsistances de ports et de vlans.
bloque
les ports qui recoivent des BPDU inconsistants
disponible sur les ios >
4.1
6. Les réglages de STP :
Port Vlan
Port-State Cost
Priority Fast-Start
Group-Method
-----
------------ -----
-------- -----------
------------------
2/1 10
forwarding 19
32 disbled
2/2
10 forwarding
19 32
disbled
6.1. détermination du path vers le Root
Aprčs que le Root bridge soit élu, l’ensemble des switchs
déterminent la meilleur topologie sans boucles.
STP utilise plusieurs costs
pour déterminer quel est le meilleur path jusqu’au Root :
- port cost
- path cost
- port priority
Quand un BPDU quitte un port il applique un cost au port. La somme de tous les cost forme le cost du path. STP regarde en 1° au path cost pour décider quels ports doivent ętre forwarding et quels ports doivent ętre bloqués. Si le path cost est égal sur plusieurs liens , STP regarde le Bridge-ID, puis le Port-ID, le plus petit gagne. Cisco permet de modifier le port ID par me paramčtre port priority.
6.2. vérification du cost du port
switch(enable) show spantree 10
1/2
Port Vlan Port-State
Cost Priority
Fast-Start Group-Method
-----
------------ ------
-------- ----------
------------------
1/2 1
forwarding 10
32 disabled
1/2 21
forwarding 10
32 disabled
…
1/2
1003 not-connected
10 32 disabled
1/2
1005 not-connected
10 4
disabled
6.3. modification de la priorité d’un port
switch(enable) set spantree portpri
1/2 20
Bridge port 1/2 port priority set to 20
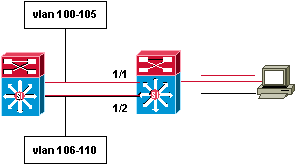
6.4. modification de la priorité par vlan :
switch(enable) set spantree
portvlanpri 1/1 16 100-105
switch(enable) set spantree portvlanpri
1/2 16 106-110
Cette commande sert ŕ répartir les vlans sur des liens
différents. Prenons l’exemple qui suit :
FastEtherChannel (FEC)
6.5. Fast et gigabit EtherChannel
4 liens redondants sont traités en tant qu’un seul lien
virtuel.
Ce lien virtuel est utilisé dans un environnement STP. FEC est bâti
sur les standards 802.3 full-duplex. Fast EtherChannel permet que des liens
parallčles soient traités par STP comme un seul lien physique.
FEC autorise
l’agrégation de 4 lien fastethernet, soit 800M en full-duplex et 2 liens
gigabit, soit 4000M en full duplex.
De plus FEC supporte le load balancing
ainsi que le management de chaque lien en distribuant le trafic sur tous les
liens du canal. Si un lien du canal tombe le trafic (unicast, multicast,
broadcast) est rerouté immédiatement.
L’allocation d’un lien se fait sur
sélection de la Mac-address, une station passe toujours par le męme lien.
La
commande show mac permet de savoir comment se fait l’allocation.
EBC :
Ethernet Bundle Controller contrôle l’activité du groupe logique et informe
l’unité logique d’assignation en cas de perte d’un lien.
EARL : Enhanced
Address Recognition Logic, l’unité de gestion de l’adresse
logique.
PAgP : Port Agregation Protocol manage le groupe logique. Son
rôle est d’aider ŕ la création automatique d’un bundle (unité logique) par envoi
de paquets au travers des ports Fast EtherChannel capable. Le protocole apprend
les voisins et si ils sont capables de supporter Fast EtherChannel. Puis le
protocole détermine si les paires sont accordées, bidirectionnelles, liens point
ŕ point et enfin il regroupe les ports qui possčdent le męme device-id ainsi que
les męme neighbour-group capability en un seul channel.
Les restrictions de
PAgP :
Tous les ports formant un channel doivent appartenir au męme vlan
ou sont configurés en tant que trunk.
Les vlans dynamiques ne peuvent
participer ŕ un channel.
Les liens ne peuvent ętre groupés dans un channel si
la vitesse ou le duplexing sont différents.
Si la vitesse ou le duplexing
d’un channel existant est modifiée, tout le channel s’en trouve modifié.
6.5.1. Les conditions ŕ l’établissement d’un Fast EtherChannel :
Tous les liens sont configurés en tant que trunk ou
appartiennent au męme vlan
Si on configure le channel en tant que trunk alors
tous les ports du channel doivent ętre configurés avec le męme mode de trunk de
part et d’autre.
Tous les liens fonctionnent ŕ la męme vitesse et sous la
męme forme de duplexing.
Un broadcast limit est configuré comme un
pourcentage pour les ports du channel.
Si le channel est composé de trunks,
tous les ports doivent ętre configurés avec le męme range vlan.
Ne pas
configurer les vlans du channel en tant que dynamique.
S’assurer que le port
security est désactivé sur l’ensemble des ports.
Enabler tous les ports d’un
channel
S’assurer que les ports d’un channel possčde bien la męme
configuration aux 2 extrémités.
Le contôle hardware du channeling du 5000
n’autorise pas tous les ports ŕ former un channel.
pour que Fast EtherChannel
fonctionne ŕ
ios > V3.1.1
6.5.2. La création d’un channel
Vérifier q’un port peut appartenir ŕ un
channel :
switch(enable) show port capabilities
[mod/port]
la création d’un channel :
switch(enable) set
port channel mod/port on | off | auto | desirable
Port(s) 1/1-2 channel mode set to
on
23/10/01,23:00:31 :PAGP-5 :Port 1/2 left bridge port
1/2
23/10/01,23:00:31 :PAGP-5 :Port 1/1 joined bridge port
1/1-2
23/10/01,23:00:31 :PAGP-5 :Port 1/2 joined bridge port
1/1-2
switch(config)#port-channel mode on | off | auto | desirable
6.5.3. La vérification d’un Fast EtherChannel
switch(enable) show port channel
1
Port Status Channel
Channel Neighbour
Neighbour
mode
status device port
-------
---------- -------------
-------------- -------------
1/1
connected on channel
WS-C5000 5/5
1/2
connected on channel
WS-C5000 5/6
Rq : Si le status apparaît disable, il convient de reconfigurer le channel
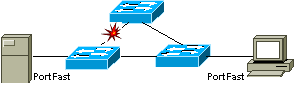
6.6. PortFast
PortFast permet de minimiser le temps de down d’un port d’un
serveur ou d’une workstation.
Les ports connectés aux serveurs ou aux
stations de travail, gérés par PortFast se reconnectent trčs rapidement en cas
de recalcul de STP. Ainsi ces ports n’ont pas ŕ attendre la convergence de STP
(50 sec).
PortFast ne tourne donc que sur les liens situés en bout de
chaîne.
switch(enable) set spantree portfast
mod/port enable
switch(enable) show spantree
mod/port
switch(config-if)#spantree
start-forwarding
6.7. UplinkFast
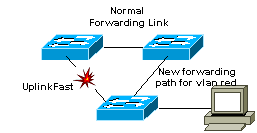
UplinkFast permet d’améliorer le temps de convergence entre
switchs. UplinkFast est configuré sur les switchs de périphérie (leaf switches).
On définit un uplink group qui contient la liste de sports forwarding et des
ports blocking. En cas de faute directe sur un switch, celui-ci bascule
rapidement sur le port blocking.
Le link 2 est forwarding par STP alors que le link 1 est
bloqué.
Backbonefast est complémentaire a uplinkfast.
Backbonefast est initié quand un root port ou un port bloqué
recoivent des BPDU inférieurs depuis le designated bridge.
Etat des ports :
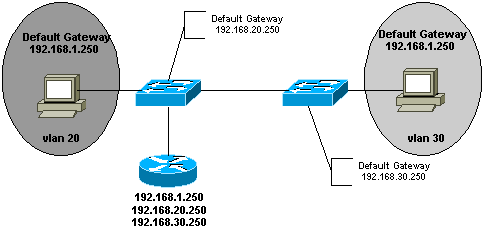
Un vlan est un domaine de broadcast. La 2° solution utilise l’encapsulation ISL. De plus dans ce
cas on configure autant de sous interfaces que de vlans, chaque sous-interface
recevant une adresse IP correspondant au subnet du vlan.
En couche distribution on trouve une combinaison de switchs
high-end ainsi que de route processors.
Le catalyst 5500 dispose de 13 slots.
Les catalyst 4000, 5000, 2926G ou 2926 sont
multimodules.
Dans le cas d’un routeur externe on utilisera router(config-if) FastEtherbet 4/0.1 ŕ configuration du
vlan 1
Dans le cas d’un routeur interne on utilise les interfaces
vlan.
La définition de la default gateway facilite la communication
inter-vlan.
Le temps de convergence passe ainsi de 30 ŕ
3 sec..
Dans l’exemple qui suit le port que STP avait passé en état
forwarding tombe (pour cause de femme de ménage qui vient de prendre les pieds
dedans et de s’allonger vertigineusement sur le plancher informatique tout en
esquivant au passage le clavier du serveur ainsi que la porte du rack entre
ouverte, mais que foutent les femmes de ménage dans ces endroits, on se le
demande, mais oů s’arrętera l’esclavagisme moderne)
Le lien dans l’état passe
trčs rapidement (3 ŕ 4 sec.) dans l’état forwarding sans passer par les états
learning et listening grâce ŕ
uplinkfast.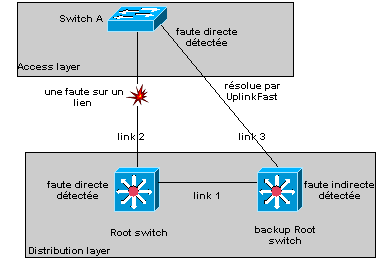
Le link 2 tombe.
Uplinkfast positionne le link 1 en forwarding
sans passer par les états learning et listening.
Le changement se fait dans
les 3 ŕ 4 sec.
Les conditions pour qu’uplinkfast reconfigure rapidement les
liens sont :
UplinkFast doit ętre activé sur le switch
Le switch doit
posséder au moins un port bloqué
l’incident doit se trouver sur le lien au
root (Root port)
Il convient de configurer UplinkFast au niveau access-layer,
uniquement sur les leaf-nodes.
la configuration
d’uplinkfast :
switch(enable) set spantree uplinkfast
enable
switch(config)#uplinkfast
Il est ŕ noter
qu’uplinkfast affecte tous les vlans d’un switch, il ne peut ętre configuré sur
un vlan individuel.
la vérification
d’uplinkfast :
switch(enable) show spantree uplinkfast
switch# show
uplinkfast
switch# show uplinkfast statistics6.8. BackBoneFast
Le principe
de backbonefast est qu’ŕ la réception de BPDU inférieurs et en cas de faute
indirecte, le switch cherche ŕ savoir s’il existe un chemin alternatif vers le
Root, auquel cas il ne déclenche pas le max. age et gagne donc 20 sec.
(précieuses).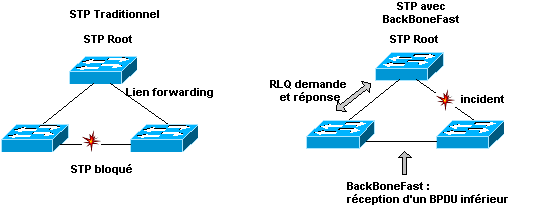
Un BPDU inférieur
identifie un switch comme étant le Root bridge et un designated bridge.
Quand
un switch reçoit un BPDU inférieur, le switch comprend qu’un lien indirect vient
de tomber (le designated bridge vient de perdre sa communication vers le Root
bridge). En temps normal, le switch ignore les BPDU inférieurs mais fait tourner
la max. age time.
Le switch essaie de déterminer s’il existe un autre chemin
vers le Root bridge. Si les BPDU rencontrent des ports bloqués, ceux-ci
représentent un meilleur chemin vers le Root bridge.
Si le BPDU arrive sur le
Root port, tous les ports bloqués représentent un chemin alternatif vers le Root
bridge. Dans ce cas le switch assume qu’il vient de perdre toutes connectivités
au Root, aprčs expiration du max. aging time, le switch devient le Root, rien
que de trčs normal sous STP.
Root Link Query BPDU :
Si le switch
possčde un chemin alternatif vers le Root, le switch utilise ce path pour
transmettre une nouvelle race de BPDU, les RLQ BPDU. Le switch envoie des RLQ
BPDU sur tous les paths alternatifs vers le Root.
switch(enable) set spantree backbonefast
switch(enable)
show spantree backbonefast
Backbonefast is enable6.9. On
récapitule les améliorations de STP :
blocking : ils ne reçoivent ni
n’envoient de trames, mais reçoivent des BPDU
listening : avant la phase
de forwarding, détermination de la route au Root
learning : populationde
la CAM table
Amélioration de STP
portfast : sur les interfaces
connectées a des serveurs ou des stations de travail. Portfast ne fonctionne que
sur les leaf-nodes ou switch de la coucha access-layer. Portfast maintient ces
ports forwarding.
uplinkfast : toyurne lui aussi sur les access switch.
Quand un root port tombe, j’utilise un port blocking.
backbonefast :
Lors d’une faute indirecte on supprime les 20 sec de max. age time.
priorités
par vlan pour le contrôle
FEC pour n’avoir qu’un seul lien logique7. Inter-vlan
routing
Un vlan ne peut donc
communiquer avec un autre vlan.
Pour ce faire il convient donc de passer en
L3 et de superposer des subnets aux vlans (et vlan).
Le routage passe par un
routeur et nécessite donc une default gateway.
Le routage peut utiliser 2
solutions distinctes :
7.1. Distribution-layer
topology
C’est au travers de cette couche que
se fait le contrôle des broadcasts, la segmentation ainsi que la terminaison des
domaines de collisions.
Le routeur intégré au switch est une carte RSM.
On
peut utiliser des routeurs high-end (7500, 7200, 4500, 4700, ces routeur doivent
posséder les fonctions de MLSP .gif) MultiLayer Switch Protocol- ios
> 11.3.4) en conjonction avec l’emploi d’une Netflow Feature Card de 5000,
NFFC ou NFFC II, pour implémenter le multilayer switching.
MultiLayer Switch Protocol- ios
> 11.3.4) en conjonction avec l’emploi d’une Netflow Feature Card de 5000,
NFFC ou NFFC II, pour implémenter le multilayer switching.
On peut aussi
utiliser des multilayer switchs :
5000 + RSM ou RSFC
(Route Switch Feature Card)
6000/6500 + MSM (Multilayer Switch Module) ou
MSFC (MultiLayer Switching Card)
RSM est un module qui fonctionne sous
ios router et autorise l’accčs du routing multiprotocole sur les interfaces
vlans. RSM apparaît comme un module possédant 2 trunks et une MAc
address.
RSFC est une carte fille installée sur un supervisor Engine IIG et
IIIG qui donne accčs ŕ toutes les fonctions d’un ios routeur.
MSM est vu
comme un routeur externe connecté par 4 ports gigabit full-duplex qui peuvent
ętre groupés en un seul channel gigabit EtherChannel, qui supporte les
encapsulations 802.1q et ISL.
Les commandes de ces 3 modules sont
identiques.7.1.1. Internal
Route Processor
Le slot 1 est
vréservé pour le Supervisor Engine Module.
Un supervisor redondant se place
en slot 2.
Le slot 23 est un slot réservé pour le processeur ATM Switch
Processor (ASP module).
Le module RSM peut s’installer dans n’importe quel
autre slot.
La communication entre le RSM et le backplane se fait au travers
des vlans 0 et 1. Vlan 0 est mappé sur le channel 0, vlan 1 est mappé sur
channel 1. Le vlan 0 est utilisé pour la communication entre le RSM et le 5000
et n’est pas accessible par les utilisateurs. Vlan 1 est le vlan par défaut. Les
vlans supplémentaires sont répartis entre les 2 channels ŕ leurs création. Un
vlan peut ętre mappé sur un channel spécifique pour balancer le trafic.7.2. La
configuration du routing inter-vlan
switch(enable) show module mod_num ŕ module 3 route
switch ŕ
session 3 Depuis le, switch on utilise un canal interne mappé sur le vlan0 et on
fait un telnet sur 127.0.0.# avec #=num_mod+1. UNe fois l’adresse IP donnée on
peut faire un telnet sur cette adresse.
La configuration du RSM est
différente de celle du switch, on peut rebooter le switch sans rebooter le
RSM.
switch> session mod_num
switch> session
3
switch> Enter Password :
router>
exit
router(config) hostname RSM
router(config)
exit
RSM#
RSM# show run
Pour clearer le nom du
router :
router(config) no hostname RSM
Autoriser un
protocole de routage :
router(config) ip
routing
router(config) router ip_routing_protocol7.2.1. Routeur
externe :
encapsulation isl 1
ip
address 10.1.1.1 255.255.255.0
router(config-if) FastEtherbet
4/0.40 ŕ
configuration du vlan 40
encapsulation isl
40
ip address 10.1.40.1 255.255.255.07.2.2. Routeur
interne :
router(enable) interface vlan
1
router(enable) ip address 10.1.1.1 255.255.255.0
router(enable)
mac-address ….
router(enable) no shutdown
router(enable)
interface vlan 40
router(enable) ip address 10.1.40.1
255.255.255.0
router(enable) mac-address ….
router(enable) no
shutdown
Un module RSM peut router jusqu’ŕ 256 vlan.
Chaque
vlan apparaît comme une interface et il convient de les activer par la commande
no shutdown.
IL convient d’utiliser une MAC-address unique pour chaque
vlan :
Permet une meilleure utilisation de Fast EtherChannel, puisqu
celui-ci se base sur la MAC-sddress pour distribuer.
Enrichît le multilayer
switching management.
Evite les problčmes en cas d’utilisation de switch 1900
dans le réseau.7.2.3. La
default gateway
switch(enable) set ip route destination
gateway metric
switch(config)# ip default-gateway
ip-address
switch(enable) show ip route
switch(config) #
show ip
! : On peut
ajouter de nombreuses routes sur un switch, ceci n’affectera pas les données qui
traverse le switch mais uniquement les communication du ou vers le switch.
Le
test du link se fait par un ping ou trace ip.